

2. 西北工业大学 自动化学院, 陕西 西安 710072
伴随着网格计算、面向服务及虚拟化等技术的发展与进步, 云计算[1]在理论及技术上得到了强有力的支持和推进, 在事实上已经成为大数据处理的核心以及未来计算模式的代表趋势。然而云计算面临一系列问题包括大规模组网、灵活的网络需求变化、动态伸缩的服务器资源网络配置、多服务商的自有接口共同对标准化的网络接口和控制提出了需求[2], 而传统的网络架构不能很好地适应这些需求的变化[3]。基于map reduce的hadoop分布式系统架构能够让用户以较低的代价应对这些问题, 进一步通过使用SDN能够从更宏观的角度对整个系统的资源进行动态调配, 从而提升系统整体性能和灵活性。
hadoop计算集群中, 为避免节点宕机, 系统会自动将输入的数据在多个节点进行备份, 数据的分片副本拷贝的存储位置对作业的响应速度影响非常大。如果为一个任务分配的计算节点上有该任务的输入数据副本, 则称这个任务为本地任务, 这个节点可以称为本地节点, 反之则称该任务为非本地任务。非本地任务在执行计算之前会先进行数据的转储, 将执行任务所需的数据从存储有该数据的节点中复制到执行任务的节点中去, 因此会大量占用网络带宽资源。保证任务的本地比率可有效提高任务执行速度、降低网络拥塞, 有利于提升整个计算集群的整体性能。
然而, 当集群中计算节点负载不均衡时, 如果仍然盲目地保障数据的本地性, 可能会导致高负载节点被分配更多任务, 进而导致该节点本地率和执行时间出现反比的情况, 造成系统性能瓶颈。因此如何根据系统实际运行情况设计一种全局最优任务调度算法成为hadoop乃至其他云计算平台中一个重要问题。
文献[4]提出一种hadoop平台上改进的JobTracker方法; Bailey等人[5]利用Qos排队机制提高基于open flow的hadoop任务的优先级; Anceaume等人[6]提出了动态系统自组织的一种严格定义, 可用于SND平台的任务自适应调用, Aroca等人[7]在此基础上实现了一种在线调度机制; Sheilchalishahi等人[8]提出的多资源的装箱算法同时考虑主机和任务队列等多个可能影响调度的因素。
本文研究并设计了一种基于SDN-hadoop的云平台网络架构, 利用SDN对于带宽的管控能力作为云计算的补充, 根据时隙策略分配带宽, 结合局部性原理决定将任务分派到本地还是低负载的其它节点, 设计一种优化的调度算法SHSA (SDN-hadoop scheduling algorithm), 从全局角度保证任务本地化比例较高的前提下以最优的方式高效分派任务, 以提高系统整体的任务处理能力。
1 SHSA任务调度算法 1.1 作业完成时间模型在hadoop集群中各个节点的能力以及整个hadoop集群的规模大小都是一定的情况下, 给节点分配任务的分配策略, 就成了影响作业完成时间的一个关键性因素。在给定一个输入数据在整个hadoop计算集群中的分布存储情况之下, 如何来给计算节点分配任务使得整个作业的完成时间最短, 就成了首要考虑的问题。因此, hadoop系统的任务调度问题, 就转化成为了如何为各个计算节点分配任务以保证最早的作业完成时间的问题。
任务设定:待分配作业被拆分为m个任务, Ti为该作业中第i个任务; 该作业的输入数据被拆分成为n份, 存放在hadoop计算集群中n个计算节点上, Nj为其中第j个节点; Si为分配到Nj上执行的Ti的输入数据块大小。
网络设定:Bj, k为Dj和Dk之间最大网络带宽; Bγl为链路实时网络带宽。
时间设定:任务Ti被分配到节点Dj, 而Ti的输入数据存放在节点NdataSrc, 则在执行任务时, 数据需要从NdataSrc转移到Dj上, 花费时间为Mi, j; 任务计算时间为Pi, j; 任务从实际分派到执行完毕的任务周转时间为Ei, j; 节点Dj执行计算时处于繁忙状态, 节点Dj由繁忙切换为空闲状态的时间为γIj, γCi, j为Ti上所有数据处理完毕的完成时间。
根据上述设定可得:

|
(1) |
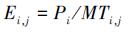
|
(2) |
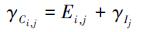
|
(3) |
对于任务Ti, 若hadoop集群中存在可用的、且能提供最早任务完成时间的节点, 则该节点被称为该任务的最优节点。同时, 只有当该作业所有任务都完成了, 才能称该作业完成了。从全局角度来看, 整个作业的完成时间是该作业中最后一个任务的完成时间。因此, 需要找到运行最慢的map或者reduce任务Ti来获得最早作业完成时间, 即:
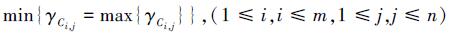
|
(4) |
根据上述设定, 综合考虑集群带宽资源, 特别是在存在很多非本地任务的前提下, 借助SDN的网络配置和带宽管理能力, 在此阐述SHSA算法的主要思想:
1) 将每一条链路的剩余带宽的占用期划分为相等的时隙Ts={Ts1, Ts2, …, Tsk}, 时隙的持续时间均为可调节参数, 其配置取决于具体网络环境。
2) 将Lγl定义为一条特定链路在某个特定时刻的剩余带宽, 如果一个map或者reduce任务Ti有在时间段 (tm, tn) 内在特定的路径上转储数据的需求, hadoop的任务调度器会利用SDN控制器来将相关的时隙提前分配给该任务, 以确保该路径上的所有链路的带宽资源在开始时隙Tsm, Tsm∈Ts到截至时隙Tsn, Tsn∈Ts之间都为Ti所保留。
3) 在hadoop系统进行任务调度之前, 利用SDN的带宽管控能力, 每当该任务Ti的计算数据被转储完毕之后, SDN控制器会释放该链路的占用, 将链路资源让给其他需要进行转储的数据。
基于时隙的带宽分配机制, 可最大化利用网络带宽能力, 从全局角度降低数据在链路之间传输所花费的时间, 从而提升了计算集群的整体性能。
1.2 SHSA任务调度流程对于任务Ti而言, 网络带宽是一种稀缺资源。因此, 在该作业的Nloc存在时, 倾向于任务的本地处理。然而, 本地节点Nloc不一定是最优计算节点, 特别是当该节点处于较高负载时, 如果仍然把任务Ti分配给节点Nloc, 则直到已有的任务全部完成 (先到先服务分派策略时) 后Ti才会得到执行, 将有可能导致系统在该时刻获得了较高的本地率, 但总执行时间却有所增加的情况。
本文考虑将数据转储时间Mi, j为任务调度的重要参数。分派任务时, 需要获取整个集群节点的负载情况, 然后尝试找到这样的一个计算最早可用节点Nminnow, 在集群中, 该节点具有最早的空闲时间γIminnow。针对Nloc和Nminnow的不同状态, 需要分别考虑3种情况:本地节点Nloc是最优节点; 远程节点Nminnow是最优节点; 本地节点Nloc在带宽受限时候是最优节点
考虑到hadoop系统可能会被多个用户所同时共享, 可用计算节点的数量n可能会少于集群总结点数量。根据以上分析, SHSA任务调度算法的具体流程如下所示:
1) 利用SDN获取实时带宽Bγl和相应的每条链路的时间间隔空闲留数比Lγl;
2) 为Ti寻找有可用空闲时间γIloc的Nminloc;
3) 为Ti寻找有可用空闲时间γIminnow的Nminnow,如果Nminnow==Nloc或γIminnow≥γIloc分配Ti给Nloc=Nminnow;
4) 如果Nloc≠null且γIminnow<γIloc,则利用 (1)~(3) 式计算γCi, minnow和所需带宽Bi, minnow,确保γCi, minnow<γCi, loc;
5) 如果Bi, minnow≤Bγl,则分配Ti给远程节点Nminnow,分配Lγl链路,同时利用 (1) 式计算Ti需要的时隙数。
2 SHSA任务调度器的设计SHSA调度器主要分为作业初始化模块等5个模块组成, 其基本调度流程如图 1所示:

|
| 图 1 SHSA调度器模块及调度流程图 |
1) 作业初始化模块:初始化用户提交的作业, 并将其添加到待执行的作业队列中。
2) 作业队列管理模块:维护待执行的作业队列, 负责管理和调度映射中的所有任务处理过程。
3) 任务分配模块:SHSA调度器进行任务调度的主模块, 执行了任务分配的主流程。
4) 作业分配池:维护一个作业分配池, 对于每一个作业维护一个这样的队列, 该队列存储了作业每一个任务分配的节点的位置。
5) 预分配模块:执行作业预分配, 在作业第一次执行时, 综合考虑本地任务和网络带宽, 为该作业预分配好其每个任务执行的节点, 并将节点队列添加进作业分配池中。
3 算法测试与结果分析测试平台由SDN控制器NOX将1个主机节点 (master)、35个从机节点 (包括4个NVIDIA TK1嵌入式超算系统和31个基于全志A20的嵌入式主计算节点) 构成的hadoop测试平台, 整个系统通过CISCO3560前兆交换机直连, 其部属示意图如图 2所示:

|
| 图 2 基于SDN的hadoop测试平台部署示意图 |

|
| 图 3 实际测试平台 |
使用TK1和A20嵌入式节点可构成具有2种不同运算能力的异构处理系统, 能更好地模拟实际运行环境。任务调度算法验证分别釆用Google标准的sort和wordcount作业进行性能测试, 设定了5种尺寸的测试样本, 2种作业实际测试结果如表 1、表 2所示。表中MT为Map占用时间; RT为Reduce任务占用时间; JT为作业总完成时间; LR为数据本地率。
| 样本 /GB | FIFO/s | BAR/s | SHSA/s | |||||||||
| MT | RT | JT | LR | MT | RT | JT | LR | MT | RT | JT | LR | |
| 0.5 | 19.1 | 25.49 | 34.2 | 0.423 | 17.1 | 26.77 | 34.91 | 0.128 | 16.6 | 23.13 | 26.41 | 0.419 |
| 1.0 | 33.7 | 33.15 | 58.97 | 0.426 | 22.6 | 47.97 | 57.24 | 0.368 | 26.6 | 31.47 | 45.09 | 0.61 |
| 2.0 | 35 | 59.91 | 80.21 | 0.494 | 37.8 | 58.18 | 83.14 | 0.251 | 36.2 | 50.14 | 71.06 | 0.555 |
| 5.0 | 70.7 | 110.2 | 171.8 | 0.675 | 60.2 | 94.44 | 142.9 | 0.298 | 75.4 | 118.6 | 137.1 | 0.72 |
| 10 | 466 | 683.3 | 973.5 | 0.774 | 489 | 534.1 | 864.1 | 0.362 | 414 | 705.8 | 832.1 | 0.809 |
| 样本 /GB | FIFO/s | BAR/s | SHSA/s | |||||||||
| MT | RT | JT | LR | MT | RT | JT | LR | MT | RT | JT | LR | |
| 0.5 | 17 | 33.13 | 37.58 | 0.387 | 18.4 | 28.95 | 39.93 | 0.179 | 19.8 | 32.22 | 42.78 | 0.293 |
| 1.0 | 29 | 56.42 | 79.63 | 0.592 | 31.9 | 53.21 | 77.85 | 0.336 | 28.8 | 48.18 | 66.98 | 0.52 |
| 2.0 | 66.1 | 119.6 | 134.8 | 0.752 | 61.7 | 106.2 | 143.6 | 0.336 | 51.5 | 96.81 | 117.2 | 0.764 |
| 5.0 | 66.2 | 153.3 | 151.6 | 0.813 | 67.2 | 133.5 | 154.2 | 0.376 | 64.1 | 132.3 | 163.2 | 0.803 |
| 10 | 336 | 588.1 | 727 | 0.84 | 345 | 592.2 | 684.5 | 0.379 | 260 | 569.3 | 627.7 | 0.808 |
对3种调度器的作业完成时间进行对比结果如图 4、图 5所示:

|
| 图 4 sort作业完成时间比较图 |

|
| 图 5 word count作业完成时间比较图 |
在sort和word count 2类作业中, 各种数据尺寸下的任务耗时都呈快速上升趋势, SHSA调度器相比FIFO和BAR作业耗时更短。主要原因是SHSA调度器则从全局视角进行任务分配, 同时考虑数据本地性和链路带宽两方面因素, 为每一个任务找到一个最优计算节点, 从而达到了整个作业的全局最优调度。而且SHSA在BAR的基础之上进一步地减小了作业的结束时间。
3.2 数据本地率的对比与分析在Sort和Wordcount测试作业执行的过程中, 记录下本地节点与非本地节点的个数, 根据表 1和表 2所得数据, 可绘制作业数据的本地率折线图, 如图 6、图 7所示。

|
| 图 6 sort作业数据本地比率 |

|
| 图 7 word count作业数据本地比率 |
大多数情况下, 数据本地化比率在50%之上, 表明本地节点在更多的情况下是最优节点, 任务选择有本地数据的节点将会有更短的完成时间。图 7中, 当作业数据大小为5 GB时, SHSA算法的本地率低于FIFO算法, 同期作业的完成时间均低于FIFO算法和BAR算法, 分析其原因本地节点任务队列长、负载较高, 而网络资源闲置, 将数据迁移到非本地节点不需要很长的时间。调度器利用这一点, 选择更有优势的非本地节点进行任务处理, 总处理时间反而较短。这也符合SHSA算法设计思路:不盲从数据本地性, 综合考虑链路带宽以及节点负载决定任务的具体分配。
4 结论本文针对大数据平台中的任务调度问题, 结合开源大数据系统hadoop设计了一种动态调度算法, 利用SDN的全局资源管理能力, 根据时隙策略来分配带宽, 并由此确定定任务分配方式, 从而能够获得较高的全局性能, 较好地避免陷入局部最优。在搭建的hadoop试验集群上对分别通过对不同尺寸的数据进行sort和word count 2组测试分别验证了本文提出的SHEA算法与FIFO、BAR算法具有更好的执行效率, 验证了算法的调度质量。
| [1] |
李强, 郝沁汾, 肖利民, 等.
云计算中虚拟机放置的自适应管理与多目标优化[J]. 计算机学报, 2011, 34 (12): 2253–2264.
Li Qiang, Hao Qinfen, Xiao Limin, et al. Adaptive Management and Multi-Objective Optimization for Virtual Machine Placement in Cloud Computing[J]. Chinese Journal of Computers, 2011, 34(12): 2253–2264. (in Chinese) |
| [2] | Xiao Luxin. Research on the Optimization of Enrollment Data Resources Based on Cloud Computing Platform[J]. International Information and Engineering Technology Association, 2015, 2(2): 9–12. |
| [3] | Hu L, Jin H, Liao X, et al. Magnet:A Novel Scheduling Policy for Power Reduction in Cluster with Virtual Machines[C]//2008 IEEE International Conference on Cluster Computing, 2008:13-22 |
| [4] | Narayan S, Bailey S, Greenway M, et al. Openflow Enabled hadoop over Local and Wide Area Clusters[C]//2012 SC Companion:High Performance Computing, Networking, Storage and Analysis (SCC), Salt Lake City, Utah, USA, 2012:1625-1628 |
| [5] | Narayan S, Bailey S, Daga A. Hadoop Acceleration in an Openflow-Based Cluster[C]//2012 SC Companion:High Performance Computing, Networking, Storage and Analysis (SCC), Salt Lake City, Utah, USA, 2012:535-538 |
| [6] | Anceaume Emmanuelle, Défago Xavier, Gradinariu Maria, Roy Matthieu. Towards a Theory of Self-Organization[J]. Lecture Notes in Computer Science, LNCS, 2006, 3974: 191–205. DOI:10.1007/11795490 |
| [7] | Aroca Jordi Arjona, Fernández Anta Antonio, Mosteiro Miguel A, Thraves Christopher, Wang Lin. Power-Efficient Assignment of Virtual Machines to Physical Machines[J]. Future Generation Computer Systems, 2016, 54: 82–94. DOI:10.1016/j.future.2015.01.006 |
| [8] | Sheikhalishahi Mehdi, Wallace Richard M, Grandinetti Lucio, et al. A Multi-Dimensional Job Scheduling[J]. Future Generation Computer Systems, 2016, 54: 123–131. DOI:10.1016/j.future.2015.03.014 |
2. School of Automation, Northwestern Polytechnical University, Xi'an 710072, China
