

2. 空军工程大学 航空航天工程学院, 陕西 西安 710038
目标跟踪是计算机视觉领域的研究热点之一,在人机交互、精确制导、视频监控等方面具有广泛应用。近年来,目标跟踪技术的研究取得了显著进展,但是当存在目标尺度变化、光照改变、遮挡及背景干扰等复杂情况时容易引起跟踪漂移,实现鲁棒、实时的目标跟踪仍然面临重大挑战。
近年来,基于检测的目标跟踪方法得到广泛关注,该类方法将跟踪视为二分类问题,利用在线训练的分类器将目标从背景中辨别出来。文献[3]将检测、学习和跟踪相结合,当目标短时间丢失后又出现在画面时,检测模块可以重新发现目标进而继续跟踪,在长时间跟踪任务中鲁棒性非常高,但该方法的跟踪模块采用光流法来估计特征点的运动,当光照变化时容易丢失目标。文献[4]将压缩感知理论应用到跟踪算法中,首先通过稀疏投影矩阵对特征进行降维,再由朴素贝叶斯分类器进行分类,获得了非常高的实时性,但在线训练分类器的过程中容易出现误差累积,对目标外观变化比较敏感。文献[5]将结构支持向量机应用于目标跟踪,该算法在线更新一组反映目标外观变化的支持向量集,将与该支持向量集相关性最大的候选样本位置作为跟踪结果,适于长时间、目标外观多变的跟踪任务。但文献[5]采用固定尺度的密集采样的方式采集候选样本,忽略了目标的尺度问题且计算量较大,而在实际应用中目标大小会不断改变,算法极易将背景信息与目标信息混淆从而导致跟踪失败。
本文在文献[5]的基础上提出一种尺度自适应目标跟踪算法,新算法引入自举滤波器对目标运动状态进行预测并生成少量多尺度候选样本,可有效克服密集采样尺度单一且计算量大的缺点;由结构支持向量机直接输出目标的估计位置,避免了在线训练分类器易发生的漂移问题。
1 传统结构输出目标跟踪算法文献[5]提出利用结构支持向量机来解决目标跟踪问题,算法实时更新一组支持向量集S,其中正支持向量保存目标的视觉特征,负支持向量保存背景中干扰物的视觉特征,在目标跟踪过程中将结构支持向量机响应值最大的候选样本位置定义为目标位置。
若已知一组图像片段集{x1,…,xn}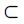 X及其标注信息{y1,…,yn}Y,则利用机器学习解决问题时需要学习一个映射函数f:X→Y实现对未知图像片段的自动标注。在结构支持向量机框架中,引入判别函数F:X×Y→R,则可以根据(1)式得到映射函数
X及其标注信息{y1,…,yn}Y,则利用机器学习解决问题时需要学习一个映射函数f:X→Y实现对未知图像片段的自动标注。在结构支持向量机框架中,引入判别函数F:X×Y→R,则可以根据(1)式得到映射函数
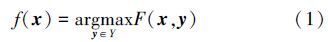
在结构输出目标跟踪算法中,若已知第(t-1)帧图像的目标位置为pt-1,在第t帧图像中以pt-1为中心采集一组尺度相同的候选样本集,则第t帧图像中的目标位置可通过(2)式得到
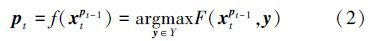
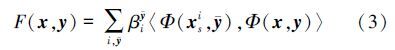
由(3)式可知对判别函数的更新本质上就是对支持向量集以及相关参数的更新。得到目标的当前帧位置pt后,在第t帧图像中以pt为中心采集一组未标签的训练样本集{(x1,y1),…,(xn,yn)},定义损失函数

定义梯度为
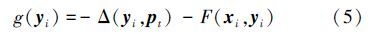
目标外观在运动过程中不断变化,支持向量集维数会不断增长,为防止由此产生的维数灾难,采用阈值策略对支持向量集的维数加以限制。当维数大于阈值时,移除引起权向量w改变最小的负支持向量(xr,y),定义如下
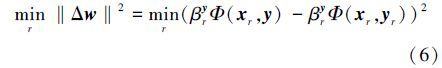
综上所述,传统结构输出跟踪算法对目标外观变化具有较强的适应性,但由于采用固定尺度的密集采样方式采集候选样本,当目标大小发生明显变化时容易跟踪失败。
2 尺度自适应结构输出跟踪算法为解决传统结构输出跟踪算法中尺度单一的问题,所提新算法利用自举滤波器的状态转移模型预测生成一组多尺度粒子集作为候选样本集,代替了密集均匀采样,实现多尺度目标跟踪的同时可有效降低算法的计算量。
2.1 自举滤波器假设动态系统的状态方程和观测方程为
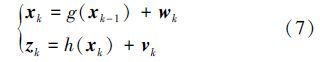
在预测阶段,假定(k-1)时刻系统的概率分布函数p(xk-1|z1:k-1)已知,则可利用概率系统转移模型来预测k时刻的先验概率p(xk|z1:k-1),即
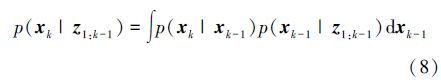
在更新阶段,假定k时刻的观测值zk已知,则所求概率分布函数可根据贝叶斯规则得到,即
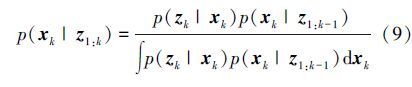
在自举滤波器框架中,k-1时刻系统的概率分布函数p(xk-1|z1:k-1)可由一组随机采样的先验粒子集{xk-1(i):i=1,…,Ns}近似表达,即
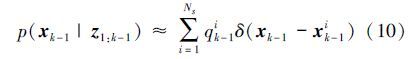
利用自举滤波器对目标运动状态进行多尺度预测可以有效解决目标跟踪中的尺度问题,定义自举滤波器的状态向量为xk=(rk,lk,sk),其中rk、lk表示样本的位置,sk表示样本的尺度。当自举滤波器的状态空间维数增大时,为了确保样本分布近似于系统的概率分布,样本数量将呈指数形式增长从而导致计算量显著增长,因此本算法假定样本的长和宽以相同的尺度sk变化。在进行目标跟踪时,首先根据目标的初始状态构建一组粒子集{x0(i):i=1,…,Ns},该粒子集将经过自举滤波器的预测步骤生成跟踪过程中的候选样本集。
在预测阶段,对于每个粒子xk-1(i),通过二阶自回归转移模型预测得到粒子当前的状态xk(i)
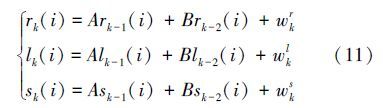
在更新阶段,利用观测模型估计每个粒子的权值。定义粒子观测值正比于结构支持向量机响应值
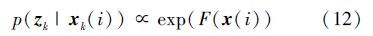
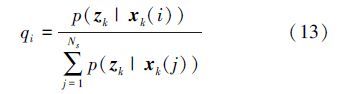
此时某些粒子的权值很小,在多次迭代后粒子集将无法充分表示系统的概率分布函数。为了避免粒子退化现象,在进行下一帧目标跟踪之前,需要对粒子进行重采样。由于粒子权值正比于该粒子的结构支持向量机响应值,所以重采样粒子集需保留具有较高权值的粒子,并重新调整粒子的分布,即
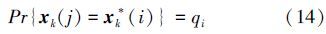
传统结构输出跟踪算法采用密集采样的方式采集候选样本,当候选区域半径为R时,样本集维数为(2R)2,而本算法根据目标的运动状态构建维数较小的多尺度样本集,可有效降低计算量。
2.3 尺度自适应目标跟踪算法本文提出的尺度自适应结构输出目标跟踪算法的具体实现步骤如下:
步骤1 初始化。读取目标的初始位置y0,提取Haar-like特征x0,分别进行粒子集和结构支持向量机的初始化:
1) 粒子集初始化。构建初始粒子集{x0(i):i=1,…,Ns},粒子权值qi=1/Ns,粒子k、(k-1)、(k-2)时刻的位置均为y0,尺度s=1。
2) 结构支持向量机初始化。将(x0,y0)作为正支持向量,梯度值最小的训练样本作为负支持向量,由SMO算法更新支持向量的系数和梯度值。
步骤2 多尺度目标跟踪:
1) 粒子多尺度预测。读取第t帧图像,根据状态转移方程式(11)对目标位置、尺度进行预测得到新的多尺度粒子集{xt(i):i=1,…,Ns}。
2) 目标定位。根据公式(3)计算每个粒子的结构支持向量机响应值,根据公式(2)确定目标在当前帧的位置pt,并根据公式(12)及(13)更新粒子权值。
步骤3 更新结构支持向量机:
1) 添加新支持向量。采集训练样本并计算梯度值,将(xt,yt)作为正支持向量,由y-=argminy∈Ygi(y)确定负支持向量,由SMO算法更新支持向量的系数和梯度。
2) 更新支持向量集。计算所有支持向量的梯度值,分别将具有最大及最小梯度的支持向量作为新的正负支持向量,然后由SMO算法更新支持向量集的系数和梯度。
3) 阈值机制。若支持向量集的维数大于阈值,则根据公式(6)移除相应的负支持向量。
4) 迭代2)、3)以提高支持向量集的准确度。
步骤4 粒子重采样。根据公式(13)得到粒子权值qi,按照公式(14)重新调整粒子的分布。
步骤5 置t=t+1,返回步骤2。
3 实验结果及分析为验证算法的有效性,在Intel Core i5-3280M,2.5GHz、4GB RAM的计算机上利用C++、OpenCV编程实现,软件环境为Visual Studio 2010。设置粒子数目Ns=400,状态转移模型参数A=1.5,B=-0.5,高斯噪声标准差分别为5、5、0.06;高斯核函数参数σ=0.2;训练样本采集半径R=20像素;支持向量集维数阈值为100,迭代次数为10。选取两段标准视频carScale、walking2以及一段机载相机拍摄的肇事车辆逃逸监控视频进行测试,由文献[7]提出的两种指标评价跟踪性能:由边界框重叠率评价准确度,重叠率越高准确度越高;由中心定位误差评价精度,误差越小精度越高。将本算法与传统结构输出跟踪算法Struck[5]及跟踪-学习-检测算法TLD[3]进行对比,重点分析本算法与Struck算法的差异。
实验1 carScale视频中的汽车快速行驶,尺度变化非常明显且存在遮挡情况。图 1为carScale视频跟踪过程中生成的支持向量集(白色和黑色矩形框分别表示正、负支持向量),可看到正支持向量反映了目标运动过程中的外观变化情况。图 2为3种算法对carScale视频的跟踪结果,图 3为3种算法的跟踪性能曲线。表 1给出了3种算法的平均重叠率、平均误差以及平均帧率。

|
| 图 1 carScale视频的支持向量集可视化 |

|
| 图 2 3种算法对carScale视频的跟踪结果(每行图像从左至右依次是第79、145、172、200和238帧) |

|
| 图 3 carScale视频的跟踪性能曲线 |
| 方法 | 平均重叠率 | 平均误差/像素 | 平均帧率/(帧·s-1) |
| Struck | 0.389 2 | 35.409 2 | 14.530 6 |
| TLD | 0.474 5 | 23.120 7 | 10.633 5 |
| 本文算法 | 0.646 5 | 16.485 0 | 19.248 1 |
随着目标尺度不断增大,Struck算法所采用的固定尺度跟踪框仅能包含目标的少部分信息,跟踪性能随目标尺度不断变大而呈指数形式降低;TLD算法具有尺度自适应性,但TLD算法的跟踪模块采用了中值光流法,对遮挡和光照变化非常敏感,从图 3可看出第150到180帧之间发生遮挡时TLD算法的跟踪误差较大。在238帧前后目标的尺度发生了显著变化,仅有本算法的跟踪框较准确的包含了目标。由表 1可见相比Struck算法,本文算法的重叠率提高了60%,误差降低了53%。当候选区域半径为R=20时,Struck约采集1 600个候选样本,而本文算法采集Ns=400个多尺度样本,大幅降低了计算量,算法实时性提高了32%。
实验2 walking2视频中的行人存在尺度变化和相似物干扰的情况。图 4为walking2视频跟踪过程中生成的支持向量集(白色和黑色矩形框分别表示正、负支持向量)。图 5为3种算法对walking2视频的跟踪结果,图 6为3种算法的跟踪性能曲线。

|
| 图 4 walking2视频的支持向量集可视化 |

|
| 图 5 3种算法对walking2视频的跟踪结果(图片依次为第180、206、241、373、500帧) |

|
| 图 6 walking2视频的跟踪性能曲线 |
当行人尺度逐渐缩小时,Struck算法的跟踪框引入了大量背景信息,跟踪性能持续降低;TLD算法对同类干扰非常敏感,在第241帧中将干扰行人误认为目标,由图 6可见在210帧及380帧前后存在遮挡时跟踪误差非常大。本算法的跟踪框始终较准确的反映了目标位置,由表 2可见本文算法的边界框重叠率相比于Struck算法提高了48%,误差降低了76%,实时性提高了60%,跟踪性能最好。
| 方法 | 平均重叠率 | 平均误差/像素 | 平均帧率/(帧·s-1) |
| Struck | 0.511 0 | 13.562 6 | 10.965 3 |
| TLD | 0.369 6 | 21.425 0 | 13.499 8 |
| 本文算法 | 0.759 1 | 3.252 6 | 17.570 2 |
实验3 选取机载相机拍摄的肇事车辆逃逸监控视频,视频中的汽车不断进行旋转、突然加速等动作。图 7为监控视频跟踪过程中生成的支持向量集(白色和黑色矩形框分别表示正、负支持向量)。图 8为3种算法对监控视频的跟踪结果,图 9为3种算法的跟踪速度对比曲线。

|
| 图 7 监控视频的支持向量集可视化 |

|
| 图 8 3种算法对监控视频的跟踪结果(每行图像从左至右依次是第73、168、200、291和367帧) |

|
| 图 9 监控视频的跟踪速度对比 |
在73帧到290帧之间汽车发生 的转向且尺度变大,Struck算法的跟踪框偏离了目标的中心位置,TLD算法在汽车旋转后仍定位到目标但跟踪框尺度自适应性不及本算法。在367帧前后目标尺度变小,Struck算法引入了大量背景信息,而本算法比TLD算法的跟踪框更准确的包含目标。由图 9中可见本算法速度相对于Struck算法有明显优势。
4 结 论本文结合实际应用背景需求,提出一种尺度自适应目标跟踪新算法。算法在传统结构输出跟踪算法的基础上,采用自举滤波器对目标运动状态进行多尺度预测,有效解决了目标尺度因距离变化或像机变焦调节等因素而变化导致的跟踪失败问题。同时避免了对图像进行密集均匀采样,降低了算法计算量。实验结果表明,该算法在目标发生明显尺度变化、部分遮挡等情况下,具有较高的跟踪精度和稳定性。
| [1] | Matteo Munaro, Emanuele Menegatti. Fast RGB-D People Tracking for Service Robots[J]. Autonomous Robots, 2014, 37(3): 227-242 |
| Click to display the text | |
| [2] | Babenko B, Yang M H, Belongie S. Robust Object Tracking with Online Multiple Instance Learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33: 1619-1632 |
| Click to display the text | |
| [3] | Kalal Z, Mikolajczyk K, Matas J. Tracking-Learning-Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(7): 1409-1422 |
| Click to display the text | |
| [4] | Zhang K, Zhang L, Yang M H. Real-Time Compressive Tracking[C]//2012 ECCV, 2012: 864-877 |
| [5] | Hare S, Saffari A, Torr P H S. Struck: Structured Output Tracking with Kernels[C]//2011 IEEE International Conference on Computer Vision, 2011: 263-270 |
| [6] | Platt J. Fast Training of Support Vector Machines Using Sequential Minimal Optimization[M]. Advances in Kernel Methods——Support Vector Learning, 1999: 185-208 |
| Click to display the text | |
| [7] | Wu Y, Lim J, Yang M H. Online Object tracking: A Benchmark[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition, 2013: 2411-2418 |
| [8] | Smeulders A W M, Chu D M, Cucchiara R, et al. Visual Tracking: An Experimental Survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(7): 1442-1468 |
| Click to display the text | |
| [9] |
马伟,陈建国,张毛磊. 基于尺度自适应和跟踪框自转的视频目标跟踪[J]. 清华大学学报, 2012,52(1): 92-95 Ma Wei, Chen Jianguo, Zhang Maolei. Video Target Tracking Based on Scale Adaptation and Tracking Box Rotations[J]. Journal of Tsinghua University, 2012, 52(1): 92-95 (in Chinese) |
| Cited By in Cnki (13) |
2. Aeronautical and Astronautical Engineering College, Air Force Engineering University, Xi'an 710038, China
