

2. 西安高科技研究所, 陕西 西安 710025
复杂嵌入式实时系统具有多种应用任务,多应用任务对嵌入式高效能计算提出了更高需求。通用计算使系统响应时间无法满足大计算量任务的实时性需求。因此,应依据应用任务及其需求的具体变化,设计面向应用驱动的计算模型,使其能够实时、动态地选择合适的计算模式。
1 相关工作目前,在飞机、智能机器人等复杂嵌入式应用领域,越来越多地采用了众核处理机。众核处理机适用于密集计算,国内外对众核处理机的研究主要集中在体系结构、资源调度、CPU+GPU异构系统相关技术以及众核应用模型[1, 2, 3, 4]的研究。
多态计算技术[5]是指在复杂嵌入环境下支持系统多级资源重构的技术,用来反映一种计算系统软、硬件结构和计算模式适应任务需求变化的思想。目前国内外对多态技术的研究热点主要集中于体系结构、资源配置和任务调度等方面[6, 7, 8]。近年来的研究结果表明,适应不断变化应用需求的一种先进模式是建立多态计算模式。文献[8]提出了一种用户满意度驱动的多态计算模型,并将多态计算与众核相结合,但仍是围绕通用移动计算而开展的研究。目前,面向复杂嵌入式实时系统应用,且将多态计算技术和众核相结合的研究相对较少。因此,本文结合众核处理机的特点,将多态计算的概念引入到众核架构中,针对复杂嵌入式实时系统应用,建立了众核多态实时计算模型,并从逻辑上实现了众核的3种计算态,为快速响应不同应用任务提供了有效支撑。
2 众核多态实时计算模型在嵌入式实时系统中,主要有3类任务:一类任务是计算复杂,需要占用系统全部可用资源以保证其时间约束;一类任务可独立并行执行;还有一类任务可被分解成若干个具有前驱后继的子任务执行。因此根据嵌入式实时系统应用特点,本文构建了一种众核多态实时计算模型,描述了众核资源上的系统服务软件及任务集,分为众核多态任务模型和众核多态实时服务模型。
2.1 众核多态任务模型2.1.1 相关概念
众核多态任务模型负责接收应用任务,并按其计算需求分为单任务、多任务分区、多任务流式3种计算模式。为有效描述众核多态任务模型,引入如下相关定义。
定义1(计算态)指众核处理单元的核资源在不同组织形式下所对应的并行计算模式。
定义2(应用任务)应用任务是系统的宏观行为目标。系统应用任务集由Γ={T1,T2,…,Tn}表示,∀Ti∈Γ称为一个应用任务。
定义3(多态计算任务)众核计算平台管理和执行的具体任务指多态计算任务,它们能够运行于众核处理机,且有不同计算形态。系统计算任务集由={PT1,PT2,…,PTm}表示,∀PTi∈称为一个多态计算任务。公式(1)描述了多态计算任务相关属性。

单任务计算态适用于计算复杂、时间约束强的应用任务,将众核运算单元内部的所有核资源同时分配给单一任务。单任务计算满足:

分区计算态适用于多个相互独立并行执行的应用任务。由于任务间相互独立,对众核资源进行划分时,会形成不同的分区,使各任务在不同的分区内执行。
将多个独立计算任务输入数据集记为Ip,=Ip={Ip1,Ip2,…,Ipn};输出数据集记为Op,=Op={Op1,Op2,…,Opn};分区任务计算需要的Kernel数记为Kp,Kp={Kp1,Kp2,…,Kpn}。其中,n表示应用任务数,Kpi表示计算任务i所需要的Kernel数。于是众核分区计算可表示为:
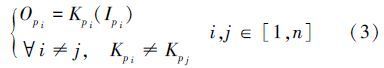
流式计算态适用于关联并行处理的应用任务,任务之间由一组具有前驱后继关系的子任务并行执行,依据计算需求及全局优化策略,将众核资源划分为多个分区,每个分区执行一个子任务,各子任务间通过共享存储机制实现数据的快速交换。
在该计算态下,计算任务可分解为多个计算步,将各计算步表示为k1,k2,…,ki,…,km,其中m代表组成计算任务的计算步(Kernel)数(i∈[1,m]); 用=Ist={Ist1,Ist2,…Isti…,Istn}代表输入数据流集合,=Ost={Ost1,Ost2,…Osti…,Ostn}为输出数据流集合,其中n表示应用任务数,i∈[1,n],则流式计算可表示为:
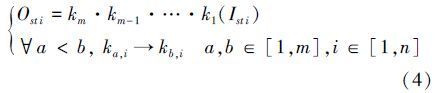
其中“·”表示用多个计算步组成一个计算任务。流式计算由多个这样的计算任务组成,每个计算任务将输入数据流Isti经由m个计算步,最终产生输出数据流Osti。 式中“→”表示依赖关系,表示第b个计算步对第i个数据流的处理必须依赖于第a个计算步对第i个数据流的处理结果,即同一数据流必须依次执行各个具有前驱后继关系的计算步。
2.2 众核多态实时服务模型众核多态实时服务模型负责屏蔽底层硬件资源的异构性,使得系统各组成部分之间可以无差别地进行数据通信。同时,为应用提供运行时系统服务,有可用资源时通过通信接口进行数据传输。
本文基于通信有限状态机模型(communicating finite state machines,CFSM)[9]构建了一种多态实时服务模型,其形式化描述如下:


|
| 图 1 基于CFSM的多态实时服务模型通信过程 |
图中的阻塞发送方式是指发送方一直阻塞直到所要发送数据传输完成后返回,非阻塞发送是指发送方在给底层协议发送数据的指令后立即返回,真正的数据传输由底层协议完成。
3 仿真测试仿真测试分为2个方面:①测试众核多态任务模型的有效性;②测试众核多态实时服务模型的通信效率。
3.1 实验设置1) 众核多态任务模型
众核多态任务模型包含3种计算态,分别用于不同类型的应用任务。以加速比为衡量依据,测试多态任务模型中3种计算态的有效性。
硬件环境为众核控制单元采用2块Intel SandyBridge E5-2609的4核CPU,每块CPU主频为2.4 GHz,15M缓存,众核计算单元采用基于Kepler K20架构的GPU,时钟频率0.71 GHz,CUDA核心数2 496。
(1) 单任务计算态:测试用例如表 1所示。当同一计算任务在计算规模增大时,分别记录运行在多核CPU和GPU上的计算时间,取加速比为多核 CPU执行时间/GPU执行时间。
| 计算任务 | 属性 | ||||
| PTID | PTpr | PTtype | PT$\tilde{I}$ | PT$\tilde{O}$ | |
| PT1 | 1 | 20 | 0 | Matrix A,B | A+B |
| PT2 | 2 | 15 | 0 | Matrix A,B | A-B |
| PT3 | 3 | 33 | 0 | Matrix A,B | A*B |
(2) 多任务分区计算态:测试2个独立的应用任务,如表 2所示,一个应用任务包含6个计算任务,另一个应用任务包含32个计算任务。为验证方便,计算任务的输入输出仍采用表 1中的数据,当计算规模变化时,测试多个计算任务并发执行和分区执行时间,取加速比为多任务并发时间/多任务分区执行时间。
| 计算任务属性 | 应用任务 | |
| T1 | T2 | |
| <PTID,PTpr,PTtype> | (PT11,PT9,PT6,PT10,PT17,PT15) | (PT4,PT5,…,PT28) |
| (<11,7,1>,<9,9,1>,…,<15,18,1>) | (<4,3,1>,<5,6,1>…,<28,18,1>) | |
(3) 多任务流式计算态:测试2个应用任务,一个由3个计算任务组成,另一个由32个计算任务组成,如表 3所示。为验证方便,计算任务的输入输出仍采用表 1中的数据,记录当计算规模变化时,多任务串行执行和多任务流式执行时间,加速比为多任务串行执行时间/多任务流式执行时间。
| 计算任务属性 | 应用任务 | |
| T5 | T8 | |
| <PTID,PTpr,PTtype> | PT2→PT7→PT5 | PT2→PT5→PT8,…, PT13→PT33→PT11→PT28 |
| (<2,4,2>,<7,10,2><5,12,2>) | (<2,4,2>,<5,14,2>,…,<28,30,2>) | |
(说明:1.应用任务T8所包含的32个计算任务中,PT2→PT5→PT8表示计算任务8依赖于计算任务5,计算任务5又依赖于计算任务2。2.不同流式任务,例如PT2→PT5→PT8和PT13→PT33→PT11→PT28可划分到不同分区。)
2) 众核多态实时服务模型
多态实时服务模型的作用是实现应用任务和硬件之间的通信交互,因此以通信接口的通信速率相比于理论峰值的衰减程度来测试多态实时服务性能。测试方法为使用1/5 000 s为时钟周期,每次传送4MB字节数据并接收到确认信息后记录1次所用的周期数,共传输128MB数据。通信速率理论峰值为1.25 Gbit/s。多态实时服务运行在主控处理机上,采用Curtiss-Wright公司VPX6-185的PowerPC。
3.2 实验结果及分析根据3.1的设置,得到众核多态任务模型及多态实时服务模型测试结果,分别如图 1、图 2所示。

|
| 图 2 众核多态任务模型测试结果 |

|
| 图 3 众核多态实时服务模型测试结果 |
图 1显示了众核多态任务模型在以不同计算态工作时获得的加速比,实验结果表明:
1) 众核工作于单任务计算态时,从图 1a)中看出,当计算规模较小时,由于启动GPU上的内核需占用一定时间,因此和多核CPU相比,获得的加速比较小,但随着计算规模增大,采用GPU计算单个任务可取得较高的加速比。
2) 众核工作于多任务分区计算态时,从图 1b)中看出,当任务数增多,计算规模增大,由于任务组中的某些计算任务占用了较多的计算资源,虽然不能达到最大的任务级并行,但在满足系统负载的情况下,分区计算态可较好的适应多个独立任务需求,缩短计算时间,提高系统对多个任务的响应速度。
3) 众核多任务流式计算态适应于多个具有前驱后继关系的任务,从图 1c)中可以看出,随着任务计算规模增大,任务之间需要传送数据和同步,采用流式计算,当后续计算任务数据到达时,前驱计算任务已经完成,该计算态不仅使GPU全局存储器充分利用,也获得了较高的加速比。
图 2表明,多态实时服务相对于系统接口的通信速率有一定的影响,但平均衰减在12%左右,能够保持通信的高效性。
4 结 论论文结合不同类型任务需求,提出了一种众核多态实时计算模型及3种计算态,并对所设计的模型进行了测试。测试结果表明,众核多态实时计算模型能较好地适应复杂嵌入式实时系统的应用需求,实现快速计算,保证对不同类型任务的快速响应。
| [1] | Gibson D, Wood D A. Forwardflow:a Scalable Core for Power-Constrained CMPs[J]. ACM SIGARCH Computer Architecture News, 2010, 38(3):14-25 |
| Click to display the text | |
| [2] |
曹仰杰, 钱德沛, 伍卫国, 等. 众核处理器系统核资源动态分组的自适应调度算法[J]. 软件学报,2012,23(2):240-252 Cao YangJie, Qian Depei, Wu Weiguo, et al. Adaptive Scheduling Algorithm Based on Dynamic Core-Resource Partitions for Many-Core[J]. Journal of Software,2012,23(2):240-252(in Chinese) |
| Cited By in Cnki (4) | |
| [3] | Anderson Boettge Pinheiro, Francisco Heron de Carvalho Junior, Neemias Gabriel Pena Batista Arruda,et al. Fusion:Abstractions for Multicore/Manycore Heterogenous Parallel Programming Using GPUs[J]. Lecture Notes in Computer Science, 2014, 8771:109-123 |
| Click to display the text | |
| [4] | Stephane Louise, Paul Dubrulle, Thierry Goubier. A Model of Computation for Real-Time Applications on Embedded Manycores[C]//2014 IEEE 8th International Symposium on Embedded Multicore/Manycore SoCs,2014:333-340 |
| Click to display the text | |
| [5] | Fernando J. Dynamically Reconfigurable Processing Engine for Polymorphic Embedded System[D]. Martinez Vallina, Chicago, Illinois, 2007 |
| [6] | Wu Yi, Zhou Xingshe, Wu Xiao, et al. An Embedded Real-Time Polymorphic Computing Platform Architecture[C]//2013 International Conference on Mechatronic Sciences, Electric Engineering and Computer,2013:2326-2330 |
| Click to display the text | |
| [7] | Arshdeep Bahga, Vijay K. Madisetti. A Dynamic Resource Management and Scheduling Environment for Embedded Multimedia and Communications Platforms[J]. IEEE Embedded Systems Letters, 2011,3(1):24-27 |
| Click to display the text | |
| [8] | Zhang Zhang, Swamy D. Ponpandi and Akhilesh Tyagi. An Evaluation of User Satisfaction Driven Scheduling in a Polymorphic Embedded System[C]//2014 IEEE 28th International Parallel & Distributed Processing Symposium Workshops,2014:263-268 |
| [9] | Brand D, Zafiropulo P. On Communicating Finite-State Machines[J]. Journal of the ACM, 1983, 30(2):323-342 |
| Click to display the text |
2. Xi'an Research Inst of Hi-Tech Hongqing Town, Xi'an 710025, China
