

在各应用场景中,大数据计算模式[1, 2, 3, 4]可分为批量计算、流式计算2种。批量计算,指先对数据收集存储,再对已经存储静态数据集中计算,发现数据价值。流式计算,指无法确定数据到来顺序和时间,也无法将历史数据全部存储,而是当数据流动进来后在内存直接实时计算数据,输出有价值的信息。
大数据批量计算技术的研究相对更成熟[5, 6],例如开源的Hadoop系统、Google的MapReduce模型等,得到广泛应用的系统就都是基于批量计算技术的[7]。对于更看重输出结果的准确性、全面性的场景,批量计算更有优势。
对于实时性要求更高、数据流量不确定、对数据准确度要求稍低的场景来说,流式计算具有明显优势[8, 9]。与大量的批量计算技术研究相比,关于流式计算的研究较少。早期的流式计算研究是以数据库环境中的流式数据计算为主。
但随着互联网大数据需求的不断增长,满足实时性、突发性、无限性分析要求的流式计算系统开始出现,例如Yahoo在2010年推出的S4流式计算系统[10]、Twitter在2011年推出的Storm流式系统、Facebook的DFP系统[11]等。这些系统各有其缺点,如何构建高可靠、高吞吐、低延迟、持续运行的大数据流式计算系统,是当前急需解决的问题。
本文分析了流式计算场景的特点,讨论了流式计算技术应该具有的主要技术特性,并基于Breiman等人在2001年提出的随机森林方法(random forest),设计了在互联网行业这一典型的大数据流式计算应用场景中的流式计算方法,并利用真实数据进行了测试,验证了方法的实际可行性。
1 介 绍 1.1 流式计算介绍流式大数据计算主要有以下特征:
1)实时性。流式大数据不仅是实时产生的,也是要求实时给出反馈结果。系统要有快速响应能力,在短时间内体现出数据的价值,超过有效时间后数据的价值就会迅速降低。
2)突发性。数据的流入速率和顺序并不确定,甚至会有较大的差异。这要求系统要有较高的吞吐量,能快速处理大数据流量。
3)易失性。由于数据量的巨大和其价值随时间推移的降低,大部分数据并不会持久保存下来,而是在到达后就立刻被使用并丢弃。系统对这些数据有且仅有一次计算机会。
4)无限性。数据会持续不断产生并流入系统。在实际的应用场景中,暂停服务来更新大数据分析系统是不可行的,系统要能够持久、稳定地运行下去,并随时进行自我更新,以便适应分析需求。
1.2 应用场景介绍互联网领域就是很好的流式大数据应用场景。该领域在日常运营中会产生大量数据,包括系统自动生成的用户、行为、日志等信息,也包括用户所实时分享的各类数据。互联网行业的数据量不仅巨大,其中半结构化和非结构化所呈现的数据也更多。由于互联网行业对系统响应时间的高要求,这些数据往往需要实时的分析和计算,以便及时为用户提供更理想的服务。
流式计算在互联网大数据中的典型应用场景如下:
1)社交网站。在社交网站中,要对用户信息进行实时分析,一方面将用户所发布的信息推送出去,另一方面也要为用户及时发现和推荐其感兴趣的内容,及时发现和防止欺诈行为,增进用户使用体验。
2)搜索引擎。搜素引擎除了向用户反馈搜索结果以外,还要考虑和计算用户的搜索历史,发掘用户感兴趣的内容和偏好,为用户推送推广信息。
3)电子商务。电子商务侧重于大数据技术中的用户偏好分析和关联分析,以便有针对性地向用户推荐商品。同时,随着大量电子商务开始内嵌互联网消费金融服务,对用户的风险分析和预警也是非常重要的。
可以预见,随着技术的不断发展、互联网与物联网等领域的不断深入连接,未来要分析的数据量必然还会爆炸性增长。传统的批量计算方式并不适合这类对响应时间要求很高的场景,能持续运行、快速响应的流式计算方法,才能解决这一方面的需求。
1.3 随机森林方法介绍随机森林是目前海量数据处理中应用最广的分类器之一,在响应速度、数据处理能力上都有出色表现[10, 13]。随机森林是决策树{h(x,θk),k=1,…}的集合H,其中h(x,θk)是元分类器,是用CART算法生成的1棵没有剪枝的回归分类树;x为输入向量,{θk }是独立而且同分布随机向量,决定每一棵决策树的生长过程。
每个元分类器h∈H,都等价于从输入空间X到输出类集Y的映射函数。对输入空间X中的每一条输入xi,h都可以得到h(xi)=yi,yi为分类器h给出的决策结果。
定义决策函数D,则分类器集合H对输入xi所得到的最终结果y就可以定义如下:
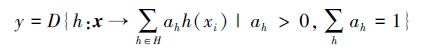
在随机森林中,单棵树的生长过程如下:
1)针对原始训练集,使用Bagging方法在原始样本集S中进行有放回的随机数据选取,形成有区别的训练集Tset。
2)采用抽样的方式选取特征。假设数据集一共有N个特征,选择其中M个特征,M≤N。每个抽取出来的训练集,使用随机选取的M个特征来进行节点分裂。
3)所有生成的决策树自由生长,不进行剪枝。每一棵决策树的输出结果之间可采用简单的多数投票法(针对分类问题)或者结果平均法(针对回归问题)组合成最终的输出结果。
随机森林方法是组合分类器算法的一种,是决策树的组合。它拥有Bagging和随机特征选择这2种方法的优点。在大数据环境下,随机森林方法还有以下优点:
① 随机森林方法可以处理大数据量,能够应对突发性数据;
② 随机森林方法生成较为简单的决策树,易于解读;
③ 随机森林方法适用于分布式和并行环境,扩展性好,适用于对分布式架构有很高要求的流式大数据处理环境;
4)决策树分类器非常简单,能以极高效率对新数据进行处理,适用于流式大数据环境下对响应速度要求高的特点;
在流式大数据环境下,随机森林方法也存在一些问题,其中最核心的问题,就是流式大数据环境中数据具有实时性和易失性的特点,经典随机森林方法难以适应。以训练集数据为基础所生成的决策树会过期,对新数据进行分类的准确度下降。
2 流式大数据环境下的算法改进 2.1 方法改进思路以往对随机森林方法的改进主要集中在几个方面:
将随机森林与Hadoop、MapReduce等计算框架结合,实现分布式随机森林方法,提高算法的处理效率。
对数据进行预处理,降低数据集的不平衡性,以此提升算法在非平衡性数据集上的准确度和分类性能。
针对标准随机森林方法采用C4.5作为节点分裂算法的情况,用效率更高的节点分裂算法如CHI2来替换C4.5,可以提高算法处理大数据集的能力。
基于分类器相似性度量和分类间隔概念,对冗余的分类器进行修剪,以取得更好的分类效果与更小的森林规模。
这几种改进方法可以有效地在特定环境下提高随机森林算法的表现,但都不能完全满足流式大数据环境对算法的要求。鉴于流式大数据算法需求所表现出来的鲜明特征,从流式大数据的特征出发,对经典的随机森林方法进行改造,思路如下:
1)使用随机森林方法实时处理数据,由于随机森林是一种比较简单的分类器,对数据的响应时间可以得到保障,能够满足实时性要求。
2)仅对一段时间内的数据进行存储,在内存可用的条件下处理少量数据,这样就可以解决流式大数据的易失性和无限性特点。
3)由于数据的无序性,经典随机森林所产生的分类器无法满足所有的输入数据,必须令分类器能够随着新数据的输入不断更新,保持对数据的敏感性和准确度。因为数据的易失性,所以分类器的更新就必须基于算法所临时保存的有限训练数据进行。
4)分类器更新方法必须是可伸缩的、高效的,不能影响到分类器对数据的正常处理。
2.2 改进后的随机森林方法首先定义随机森林中决策树h的准确度(accurate)Ah:
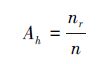
在回归问题中,决策树h给出的分类结果如与最终结果一致,则认为该决策树得出了正确结果。计算决策树h给出结果xi与最终结果之间的差值,并取其标准差作为h的准确度:
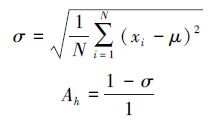
1)按照标准的随机森林方法构造决策树群H。
2)为每一棵决策树h,h∈H建立1张记录表Th,记录随机森林在处理数据过程中生成的结果。
3)一段时间后,对所有决策树的结果记录表进行扫描,删除其中准确度最低的树。
通过准确度进行筛选后,森林中树的数量会越来越少,实现决策树集的剪枝。但数量的过分减少,也会造成整个决策树集在准确度上的降低[11]。
为了保持一定数量的决策树,在剪枝的同时,也要对数据集进行跟踪,生成新的决策树来保持整个森林的质量。为了从数据集中筛选出对生成新的决策树更有用的样本,引入间隔(margin)定义如下: 间隔指随机森林在1条给定样本数据(x,y)上的整体决策正确度,定义为:
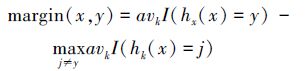
margin(x,y)大于零的样本,说明决策树集可以得到正确结果。与已有的决策树相似度高的树并不会提高整个森林的准确度,此类样本不需要再次处理。为了让新生成的决策树能够提高整个森林的准确度,记录margin(x,y)小于等于零的样本,形成新的训练数据集S′。数据集S′的特点,是只占当前数据集S中的一小部分,但其数据特征与其他数据不同。
在数据集S′上使用随机森林方法,获得一个新的决策树集合{h′(x,θk),k=1,…}。数据集S′只代表了全部数据集中的一部分数据,在S′中筛选一定比例的决策树,加入原来的决策树集合中。
根据S′与S之间的比例确定要筛选出的决策树数量:
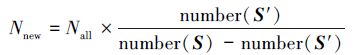
筛选方法可以有以下几种:
S′筛选法:利用S′进行检验,并按照准确度对所有决策树排序,选择其中准确度最高的Nnew棵决策树。
S筛选法:利用全部数据集S进行检验,并按准确度对所有决策树排序,选择准确度最高的Nnew棵树。
Margin筛选法:计算每棵树在数据集S′上的margin均值与margin方差之比[18],作为每一棵决策树的重要性衡量指标,选择最重要的Nnew棵树。
改进后的随机森林方法流程如图 1所示。

|
| 图 1 改进后随机森林方法流程图 |
① 使用初始训练数据集S生成最初的随机森林H;
② 使用随机森林H对当前待处理的数据集Si进行分类:
a) 用随机森林中的每一棵树hj对Si中的每一条数据xj进行分类;
b) 记录每一棵树和每一条数据的分类结果,同时计算该条数据分类结果的间隔值margin(xj,y);
c) 如果margin(xj,y)小于给定阈值,则将xj加入新训练数据集S′。
③ Si分类完毕后,计算每棵树的准确度,并进行剪枝;
④ 在新训练数据集S′上执行随机森林方法,生成新的随机森林H′;
⑤ 对新的随机森林进行剪枝,将剪枝后的H′与H合并,形成新的随机森林H;
⑥ 清空训练数据集S′,开始处理下一批数据。
2.3 新随机森林方法的优点新的随机森林方法有着以下优点:
1)新方法每次所处理的数据集是有限的,在实际应用中,可以根据内存大小设计每次处理的数据集大小,保证数据的实时计算和计算效率;
2)新方法中,需要存储的只有结果记录表和新训练数据集,相比原始数据流小了很多,满足流式大数据的易失性特点,在大数据量下的伸缩性更好;
3)对新数据的处理只需要使用随机森林进行验证和投票,执行效率高,能够实时反馈数据的处理结果;
4)该系统可以持续地更新运行下去,并能够不断使用数据的新特性来更新自身,满足流式大数据环境的无序性和无限性特点。
3 数据验证 3.1 测试数据集测试数据集为来自互联网行业的客户信息数据。数据量为20万条,5年时间跨度,每个季度的数据量为1万条。数据包括1个目的类别(客户值:高/低)和如表 1所示的16个特征属性。
| Name | Value |
| Age | 0~100 |
| Gender | Male / Female |
| Marriage | Y/N/D |
| City | Beijing,Shanghai… |
| Job | Farmer,Teacher… |
| Title | Manager,VP… |
| Education | High school,College… |
| Salary | 0~1 000 000+ |
| Yearly Income | 0~10 000 000+ |
| Family Size | 0~10 |
| Child Number | 0~10 |
| House Type | Own,Rent.... |
| Purchases | 0~1 000 000+ |
| Activity | 0~1 000 000+ |
| Preference | 0~1 000 000+ |
为了验证改进后随机森林算法的有效性,使用第1年第1季度的1万条数据作为初始化训练集,利用这些数据建立最初的随机森林,树的数量ntree=100。
3.2 数据模式的变化对算法的影响以第1年第1季度的1万条数据作为初始化训练集,建立随机森林,并利用建好的随机森林对后面的流式客户数据进行处理,每个季度为1个周期。随着时间的变化,原有随机森林会逐渐变得不适应新的数据,客户价值评级的准确度随时间降低,从第1季度的93%下降到第5年的81%。
定义剪枝数量为50%,用改进后的随机森林方法生成新的决策树,加入到原有的随机森林中。使用2.2节所描述的不同决策树筛选方法,改进后的随机森林方法表现如图 2所示。

|
| 图 2 改进后随机森林方法的准确度比较 |
可以看到,与原有的随机森林方法相比,改进后的随机森林方法对数据模式的变化有明显更好的适应性,随着时间的变化整个森林也在缓慢更新,改进后方法的准确度一直稳定保持在90%以上。
在筛选新决策树的方法中,使用在新样本数据集S′上的准确度进行筛选(S′筛选法)和使用每棵树的margin均值与margin方差之比筛选(margin筛选法),都可以得到很好的效果,方法之间差别很小。使用数据集S进行筛选的方法(S筛选法)也可以提高准确度,但其准确度逐渐下降到87%,不如另外2种方法。
假设不考虑内存限制,在每一季度结束后使用另外2种模式来更新随机森林:
模式1:每次都使用从最开始到当前的全部数据来重新训练生成随机森林;
模式2:每次都使用上一季度的全部数据来重新训练生成随机森林;
模式3:使用新的随机森林方法来训练生成随机森林;
以上3种模式下的随机森林方法表现如图 3所示。

|
| 图 3 不同模式随机森林方法的准确度比较 |
可以看到,模式3的准确度是最优的,模式2的准确度稍差,但是也较为平稳,模式1的准确度最差,随数据量增大下降较快。
这3种模式分别所需要耗费的存储空间如图 4所示。

|
| 图 4 不同模式随机森林方法所需存储比较 |
可以看出,模式1所需要的存储空间随时间和数据量线性增长,所需要的空间最大。模式2所需要的存储空间与每个周期的总数据量相关,比模式1要少很多,在流量变化不大时会保持平稳。模式3所需要的空间最少,远小于模式2,而且其波动幅度仅与算法当前准确度有关,与总的数据流量关系不大。
4 结 论本文在原有随机森林方法的基础上,提出了一种能够适应流式大数据环境的新随机森林方法。新的方法可以在流式大数据只经过分类器1次的情况下工作,不需要对海量的历史数据进行存储和扫描,对存储空间的要求很低;还可以根据流式大数据的变化进行自我调整,适应新的数据,在保证数据吞吐量和处理效率的同时,保持对数据的处理准确度。
在使用真实互联网行业流式大数据场景试验表明,新的随机森林方法可以解决互联网行业流式大数据场景所遇到的实际问题,验证了其有效性。
但该方法在其他类型的数据集上是否通用,剪枝的判定函数是否还可以有所提高,新决策树所占的比例应该是多少合适以及如何将改进后的随机森林算法与Storm、S4等分布式大数据处理架构结合,实现更好的系统容错、资源调度、负载均衡性能等有待探讨。
| [1] | 孟小峰,慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013, 50(1): 146-169 Meng X F, Ci X. Big Data Management: Concepts, Techniques and Challenges[J]. Journal of Computer Research and Development, 2013,50(1):146-169 (in Chinese) |
| Cited By in Cnki (905) | Click to display the text | |
| [2] | Lim L, Misra A, Mo T L. 基于节能智能手机的连续处理传感器数据流自适应数据采集策略[J]. 分布式和并行数据库, 2013,31(2):321-351 Lim L, Misra A, Mo T L. Adaptive Data Acquisition Strategies for Energy-Efficient, Smartphone-Based, Continuous Processing of Sensor Streams[J]. Distributed and Parallel Databases, 2013,31(2): 321-351 (in Chinese) |
| [3] | Li B D, Mazur E, Diao Y L. SCALLA: 可伸缩的单通过分析用Map Reduce平台[J]. ACM数据库系统通讯, 2012, 37(4): 1-43 Li B D, Mazur E, Diao Y L. SCALLA: A Platform for Scalable One-Pass Analytics Using Map Reduce[J]. ACM Trans. on Database Systems, 2012, 37(4): 1-43 (in Chinese) |
| [4] | Yang D, Rundensteiner E A, Ward M. 数据流中的邻近模式挖掘[J]. 信息系统, 2013,38(3):331-350 Yang D, Rundensteiner E A, Ward M. Mining Neighbor-Based Patterns in Data Streams[J]. Information Systems, 2013,38(3):331-350 (in Chinese) |
| [5] | 李国杰, 程学旗. 大数据的研究现状与科学思考[J]. 中国科学院院刊, 2012,27(6): 647-657 Li G J, Cheng X Q. Research Status and Scientific Thinking of Big Data[J]. Bulletin of Chinese Academy of Sciences, 2012,27(6): 647-657 (in Chinese) |
| [6] | 王元卓, 靳小龙, 程学旗. 网络大数据:现状与展望[J]. 计算机学报, 2013,36(6):1125-1138 Wang Y Z, Jin X L, Cheng X Q. Network Big Data: Present and Future[J]. Chinese Journal of Computers, 2013, 36(6): 1125-1138 (in Chinese) |
| Cited By in Cnki (233) | Click to display the text | |
| [7] | 覃雄派,王会举,杜小勇,王珊. 大数据分析——RDBMS与MapReduce的竞争与共生[J]. 软件学报, 2012,23(1):32-45 Qin X P, Wang H J, Du X Y, Wang S. Big Data Analysis: Competition and Symbiosis of RDBMS and Map Reduce[J]. Ruan Jian Xue Bao/ Journal of Software, 2012,23(1): 32-45 (in Chinese) |
| Cited By in Cnki (2) | Click to display the text | |
| [8] | Kobielus A. 大数据架构中流式计算技术的角色. 2013. http://ibmdatamag.com/2013/01/ the-role-of-stream-computing-in-big-data-architectures/ Kobielus A. The Role of Stream Computing in Big Data Architectures. 2013. http://ibmdatamag.com/2013/01/ the-role-of-stream-computing-in-big-data-architectures/ (in Chinese) |
| [9] | 孙大为, 张广艳, 郑纬民. 大数据流式计算:关键技术及系统实例[J]. 软件学报, 2014(4): 839-862 Sun D W, Zhang G Y, Zheng W M. Big Data Stream Computing:Technologies and Instances[J]. Journal of Software, 2014(4): 839-862 (in Chinese) |
| Cited By in Cnki (0) | Click to display the text | |
| [10] | Neumeyer L, Robbins B, Nair A, Kesari A. S4: 分布式流计算平台. 第十届IEEE数据挖掘国际会议(ICDMW 2010). Sydney: IEEE Press, 2010. 2010.170-177 Neumeyer L, Robbins B, Nair A, Kesari A. S4: Distributed Stream Computing Platform. In: Proc. of the 10th IEEE Int'l Conf. on Data Mining Workshops (ICDMW 2010). Sydney: IEEE Press, 2010: 170-177 (in Chinese) |
| [11] | Borthakur D, Sarma JS, Gray J, Muthukkaruppan K, Spigeglberg N, Kuang HR, Ranganathan K, Molkov D, Mennon A, Rash S, Schmidt R, Aiyer A. 脸书中Apachi Hadoop的实时应用. ACM数据管理国际会议 (SIGMOD 2011 and PODS 2011). Athens: ACM Press, 2011: 1071-1080 Borthakur D, Sarma JS, Gray J, Muthukkaruppan K, Spigeglberg N, Kuang HR, Ranganathan K, Molkov D, Mennon A, Rash S, Schmidt R, Aiyer A. Apache hadoop goes realtime at Facebook. In: Proc. of the ACM SIGMOD Int'l Conf. on Management of Data (SIGMOD 2011 and PODS 2011). Athens: ACM Press, 2011: 1071-1080 (in Chinese) |
