

软件故障定位是软件调试过程中最为耗时和合耗资源的活动之一。为了减轻程序员手工排查程序语句的工作量,提高代码调试效率和可靠性,研究人员提出了一系列自动化的故障定位方法。机器学习方法被广泛采用。基于监督学习方法应用较广,且可靠性高。但是存在一个重要问题,就是大量标记样本的获取,因为在实际项目中大量标记样本的获取极其困难且代价高昂[1]。
针对标记样本获取困难这一问题,本文提出基于半监督学习的软件故障定位方法,应用Zhou等人给出的一种命名为Co-Trade的协同训练风范的半监督学习算法[2],同时使用软件静态属性和动态属性进行协同训练分类,从而实现软件故障定位。本文采用的软件故障定位模型基于语句级别。
1 基于机器学习的软件故障定位机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法,已广泛应用于各个领域。在软件故障定位中,也已经取得一定研究成果。
1.1 基于监督学习软件故障定位监督学习是学习器通过对有标记的训练样本进行学习,建立模型用于预测未知示例样本的标记。
Wong等人[4, 5]先后提出基于BP神经网络和RBF神经网络的软件故障定位模型,在这2个模型中,每个测试用例的覆盖信息(覆盖了哪些语句)和相应执行结果(成功或失败)构建成一张二维表,用于训练BP/RBF神经网络。然后用这种学习了测试用例与语句之间覆盖关系的神经网络模型对虚拟测试用例(每个测试用例只覆盖一条语句)进行预测,从而得到每条语句包含bug的可能性。
Briand等[6]采用C4.5决策树从测试用例输入输出中识别出导致测试失败的条件,认为相同条件下执行失败的测试用例由相同原因导致,因此对失败测试用例覆盖的语句进行归类和排名,从而达到对Tarantula语句可疑度排名的改进。
然而,大量实验结果和文献数据表明数据的质量和比例是训练良好的分类器进行故障定位的2个重要因素。但是,准确可靠的软件质量标签只有经过详尽、完整的软件测试和对错误的精确定位才能得到,并且源代码中错误语句的比例要比正确语句的比例低得多,此过程耗时较长且成本较高。因而,这些都限制了基于监督学习软件故障定位算法的发展和实际项目应用。但是,如果放弃这些标记样本,仅仅使用无标签的样本数据进行无监督学习又会使得标记的样本数据失去价值,且非监督学习效果并不理想。因此,怎样更好地利用这2种数据成为一个很受关注的难题。为了解决这一困难,人们提出了半监督学习方法,该方法能够同时利用好这2种样本,达到更好的分类结果。
1.2 半监督学习技术在软件故障定位中的应用半监督学习的基本设置是给定一个来自某未知分布的有标记示例集以L={(x1,y1),(x2,y2),…,(x|L|,y|L|)}及一个未标记示例集U={x1,x2,…,x|U|,期望函数f∶X→Y可以准确的对示例x预测其标记y。这里xi,x′j∈X均为d维向量,yi∈Y为示例xi的标记,|L|和|U|分别为L和U的大小,即它们所包含的示例数。
在软件故障定位中,目前尚未有基于半监督学习进行软件故障定位的研究成果。本文通过对软件故障定位技术及特点的分析,以及半监督学习算法进行学习研究,结合实际项目标记样本获取困难且成本高昂的实际情况,提出采用一种协同风范的半监督学习算法——Co-Trade进行软件故障定位。
2 基于Co-Trade算法故障定位模型本文采用的软件故障定位模型中,故障定位基于语句级别,我们将程序中的语句作为样本。假设程序P由语句集S构成,对于S中的任意一条语句s,其分类结果有2种可能性:True或者False,我们用结果True表示该语句不包含任何故障,用False表示语句包含故障,从而确定出故障存在的位置。
2.1 Co-Trade算法优点Co-Training 算法在文本处理方面具有绝对优势,在对经典半监督学习算法进行分别学习和对比后,我们选择Co-Training作为基础。 Co-Trade算法是Goldman 和Zhou[2]在Co-Training算法基础上提出的一种基于切割边缘权重统计的数据编辑技术进行优化的算法。该算法在测试标记的准确性、确定标记的可信度以及确定下一迭代的新标记数据方面进行了改进。在测试标记的准确性上,Co-Trade算法中采用了多次交叉十倍验证的方法;在确定标记的可信度方面,使用基于切割边缘权重统计的数据编辑技术。因此其分类可信度比Co-Training算法要高。
2.2 Co-Trade算法描述Co-Trade 算法是Co-Training算法基础上加入了可信度计算,从而达到训练处高可信度分类器的效果。因此,我们首先在算法1中对标准协同训练算法Co-Training进行描述。Co-Training要求数据集有2个充分冗余视图,即满足如下条件的数据集:①每个数据集都足以描述该问题;②每个属性都条件独立于第二个数据集。标准的协同算法在2个视图上利用有标记示例分别训练出一个分类器。然后,在协同训练过程冲,每一个分类器从无标记示例中挑选出若干可信度较高的示例进行标记,并把标记后的示例进行更新。不断迭代进行,直到达到特定条件。
算法1 Co-Training算法
输入:
标记数据集合L
无标记数据集合U
算法步骤:
Step1 建立无标记数据池U′,用来存放U中随机抽取的无标记数据;
Step2 循环K轮;
Step2.1 利用L与x1视图训练出分类器h1;
Step2.2 利用L与x2视图训练出分类器h2;
Step2.3 利用h1从U′中标记出p个正类和n个负类示例;
Step2.4 利用h2从U′中标记出p个正类和n个负类示例;
Step2.5 将这些新标记数据加入L;
Step2.6 从U中随机抽取2p+2n个无标记示例至U。
Step3 退出循环。
输出: 经过训练的分类器h1和h2。
Co-Trade算法的改进核心是加入了样本可信度计算,从而选择可信度较高的样本对分类器进行训练,最终得到置信度较高的分类器。算法2是对可信度计算方法的具体描述。
算法2 样本标记可信度计算
假定有一个图G:图的每一个顶点代表一个标记示例(zp,yp)。
Step1 判断G中任意2个顶点zp和zq,若zp属于zq的最近K个邻居。若是,则进入Step2,否则进入Step3;
Step2 在zp和zq间建立一条边pq;
Step3 重复Step2,并给边pq赋予权值wpq=(1+d(zp,zq))-1(wpq∈[0, 1]),其中d(zp,zq)为zp和zq之间的欧几里得距离;
Step4 判断pq连接的2个顶点是否有不同的标记值,即yp≠yq,若是,则定义此边为切边(cut edge),同时Ipq=1,否则Ipq=0;
Step5 计算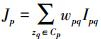 ,其中Cp是点zq的最K邻近集合;
,其中Cp是点zq的最K邻近集合;
Step6 由大数定律推得(zp,fq)的可信度为:CFz(zp,yq)=1-Φ(Jps)。
在确定下一迭代的新标记数据方面,Co-Trade依旧考虑了新标记数据的噪声问题。若视图1确定的新标记数据为f1Δ(u′1),那么加入视图2训练器的噪声率ηbu′1为:

最终由Angluin&Laird 噪音学习理论可以得到Co-Trade每次迭代错误率的准确值为:
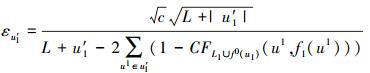
最终我们只要求得使错误率最小的新标记数据集合,并把它加入另一个分类器的下一轮训练数据集合中即可。Co-Trade 算法可以支持朴素贝叶斯NB、支持向量机SVM以及决策树CART 3种分类器。
2.3 故障定位特征选择Jones等人[7]认为程序语句存在故障的可能性与它被失败用例执行的次数正相关,提出了用颜色可视化表示语句存在故障的可疑程度,并实现了可视化故障定位工具Tarantula。
基于Tarantula启发,对于每条可执行语句,我们给出覆盖该语句的测试用例执行成功比率和语句的测试用例覆盖率2个动态属性,分别用Ssr,Scr表示;同时,我们选择5个在软件故障预测中常用的静态属性协同进行故障定位,分别为:
1)语句所包含操作符个数:Soc;
2)函数复杂度:Fcmt;
3)语句行数:Flc;
4)最大深度:Fmd;
5)内部函数调用次数:Ffc。
2.4 评价指标本文算法应用中,将正确程序语句称为正样本,错误语句称为负样本,测试程序集中所有可招待语句最终都会得到一个分类结果,即为正或者为负。因此,可以采用机器学习分类中的2个衡量指标对故障预测性能进行评价,即分类准确率和查全率:
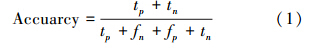
式中,tp表示分类结果为正且预期结果也为正(True Positive);tn表示实际分类结果为负且预期结果也为负(True Negtive);fp表示实际分类结果为正而预期结果为负的(False Positive);fn表示实际分类结果为负且预期结果亦为负的(False Negtive)。
3 实验及结果分析 3.1 Siemens Suite实验数据集本文采用Siemens Suite作为算法评价数据集。Siemens Suite是一组开源的用于评测软件故障定位方法和工具的数据集,自从2003年被引入用于评价NNQ法的有效性后,被广泛采用以评估错误定位技术的有效性。本次实验中我们选择了其中3个程序,具体信息如表1所示:
| Program | Number of faulty versions | Number of executable statements | Number of test cases |
| Schedule2 | 10 | 112 | 2 710 |
| tcas | 41 | 55 | 1 608 |
| Tot-info | 23 | 113 | 1 052 |
我们将所选择的3个程序在matlab中分别在监督学习算法和Co-Trade算法中进行实验,获得各自分类准确率和错误定位准确率。
1)数据处理
由于实际项目中的正确样本和错误样本比例较高,Siemens Suite也不例外,即数据挖掘中的数据倾斜较严重,这会严重影响分类器训练效果,因此,本次实验中我们采取规避的方法,对实验数据进行预处理,所有错误语句全部保留,而正确语句按照正负比例5:1随机选择其中一部分纳入实验。
2)样本分配
用L-data表示标记样本,U-data表示未标记样本,T-data表示测试样本;为了达到半监督学习效果,在CoTrade算法应用中,未标记样本的数量我们按照L-data∶U-data<1∶7的规则进行未标记样本数量控制;而测试样本与标记样本的比率按照L-data∶T-data<1∶2规则控制。
3)属性划分
协同训练中,需要同时训练两个分类器,我们将动态属性分为一组,静态属性分为另外一组。Tcas实验数据的标记样本如表2、表3所示:
| 测试语句 | Ssr | Scr | Result |
| S1 | 0.955 674 | 0.350 746 | 0 |
| S2 | 0.922 122 | 0.550 995 | 1 |
| S3 | 0.922 122 | 0.550 995 | 0 |
| S4 | 0.985 425 | 0.981 343 | 1 |
| S5 | 0.985 425 | 0.981 343 | 0 |
实验中,对同一组数据集,我们在Co-Trade算法和相应监督学习分类算法中所采用的标记样本和测试样本相同,3组程序所获得的试验结果如表4所示:
| 测试 程序 | 分类器 类型 | 分类准确率/% | 故障查全率/% | ||
| Co-Trade监督学习 | Co-Trade监督学习 | ||||
| schedule | SVM | 57.15 | / | 100.00 | / |
| NB | 85.72 | 72.73 | 100.00 | 50.00 | |
| CART | 85.72 | 63.64 | 100.00 | 10.00 | |
| tcas | SVM | 45.45 | / | 100.00 | / |
| NB | 54.55 | 72.73 | 100.00 | 25.00 | |
| CART | 81.82 | 36.36 | 100.00 | 100.00 | |
| tot-info | SVM | 50.00 | / | 90.91 | / |
| NB | 70.00 | 54.55 | 90.91 | 90.91 | |
| CART | 80.00 | 63.64 | 90.91 | 36.36 | |
根据在Siemens Suite数据集中的实验结果,我们可以得到如下结论:
1)在标记样本数量相同情况下,采用相同分类器,Co-Trade算法的分类准确率整体高于监督学习算法;
2)在故障查全率指标中,Co-Trade算法在schedule和tcas中均可以达到100%,没有错误语句的遗漏;在tot-info中,也达到90.91%,故障查全率非常稳定。而监督学习算法,由于标记样本数量较少,其预测准确率和故障查全率平均水平都比较低,稳定性也比较差。
3)SVM分类器在本次实验监督学习过程中,由于标记样本数量过少,无法达到训练分类器效果,因此没有得到监督学习实验数据。
4)在同一组实验中,Co-Trade算法采用决策树分类器(CART)效果最优,朴素贝叶斯(NB)其次,支持向量机表现最差。
4 结 论本文将半监督学习方法应用于软件故障定位中,为软件故障定位给出了一种新思路。实验表明,在标记样本数量较少的情况下,使用Co-Trade算法进行软件故障定位的准确率和故障查全率都高于传统监督学习方法,且错误遗漏情况极少。
我们的后期工作将主要集中在两个方面:1)研究半监督学习领域解决数据倾斜的算法,找到解决软件故障定位中正负样本严重不平衡问题的有效方法;2)将半监督学习算法应用于更多数据集以及不同领域实际项目(如电子商务系统,Web 服务等)的软件故障定位中,验证其适用范围和有效性。
| [1] | Binkley D. Source Code Analysis: a Road Map[C]//Proceedings of Future of Software Engineering, Minneapolis, USA, 2007: 104-119 |
| Click to display the text | |
| [2] | Zhang M L, Zhou Z H. CoTrade: Confident Co-Training with Data Editing[J]. IEEE Trans on Systems, Man, and Cybernetics, Part B: Cybernetics, 2011, 41(6): 1612-1626 |
| Click to display the text | |
| [3] | Ali S, Andrews J H, Dhandapani T, et al. Evaluating the Accuracy of Fault Localization Techniques[C]//Proceedings of the 2009 IEEE/ACM International Conference on Automated Software Engineering, 2009: 76-87 |
| Click to display the text | |
| [4] | Wong W E, Debroy V, Golden R, et al. Effective Software Fault Localization Using an RBF Neural Network[J]. IEEE Trans on Reliability, 2012, 61(1): 149-169 |
| Click to display the text | |
| [5] | Wong W E, Qi Y. BP Neural Network-Based Effective Fault Localization[J]. International Journal of Software Engineering and Knowl6edge Engineering, 2009, 19(4): 573-597 |
| Click to display the text | |
| [6] | Briand L C, Labiche Y, Liu X. Using Machine Learning to Support Debugging with Tarantula[C]//The 18th IEEE International Symposium on Software Reliability, 2007: 137-146 |
| Click to display the text | |
| [7] | Jones J A, Harrold M J, Stasko J. Visualization of Test Information to Assist Fault Localization[C]//Proceedings of the 24th International Conference on Software Engineering, 2002: 467-477 |
| Click to display the text |