

2. 陕西省行政学院计算机系, 陕西西安 710068
随着高科技和生产力的迅猛发展,各类大型机械设备的智能化程度不断提高,结构日趋复杂,设备的造价也越来越高,对机械设备的可靠性提出了更高的要求。近几年,国内外因机电设备故障而引起的灾难性事故屡屡发生,不但造成了巨大的经济损失而且经常还有重大人员伤亡[1]。因此,机械设备故障诊断技术逐渐受到广泛关注,对机械设备进行故障诊断,实质上就是根据获得的各种信息对设备状态进行分类识别,然后对信息进行智能处理并辅助专家进行机械故障诊断[2]。目前,机械设备故障诊断大多使用从各种信号信息处理的结果中提取的少数特征量来判断系统的状态,信号绝大多数是非平稳、非线性的,而信号处理结果大部分往往是数据量很大,维数很高的图像数据,如时域的振动波形、轴心轨迹;频域的功率谱、幅值谱等。另外,随着一些新的信号分析手段如时频分析、小波变换、非线性谱等被引入到机械设备故障诊断领域,以高维图像形式表示的分析结果越来越多[3]。如何从高维图像中获取敏感特征是当前故障诊断领域中面临的一项十分困难的任务,目前,国内外在基于图像(时域、频域波形,时频分析图形、小波分解图形等)特征提取与支持向量机、神经网络、遗传算法、人工免疫算法等相结合的故障诊断方法的研究与应用方面已经作了大量的研究工作,但在具体应用过程中存在局限性而不能满足生产的需要[4,5,6]。因此,针对上述问题,本文提出了基于多核非负矩阵分解(multi-kernel non-negtive matrix factorization,MKNMF)的机械设备故障诊断方法,该方法不需要对机械设备信号处理获得的图形或图像提取特征,而是应用多核非负矩阵分解方法进行降维,并结合多核支持向量机(Multi-Kernel Support Vector Machine,MKSVM),实现对降维后的数据直接进行识别。大大降低原始数据特征的维数,节省存储资源,提高运算效率以及故障诊断的识别率。
1 多核非负矩阵分解理论 1.1 非负矩阵分解非负矩阵分解(nonnegative matrix factorization,NMF)是在矩阵中所有元素均施加了非负约束条件下,对矩阵进行分解的算法[7]。非负矩阵分解是一种多变量分析方法,用Vn×m代表m个n维空间的样本数据,该数据矩阵中各个元素都是非负的,表示为V≥0。对矩阵Vn×m 进行线性分解,如(1)式所示:
式中,Wn×r称为基矩阵,其为原始机械故障信息矩阵分解后r按列堆叠的机械故障特征基图像组成的基图像矩阵;Hr×m 为系数矩阵,表示合成每幅故障图像时每个基图像对应的权值矩阵。按照以上方法就可以实现对原始信息数据矩阵的降维,得到数据特征的降维矩阵。通过对监测数据进行非负矩阵处理节约存储空间的可计算资源,从而提高数据分类效率。 1.2 核非负矩阵分解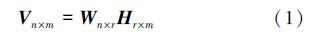
为了解决传统非负矩阵分解效率较低的问题,通过将核方法引入非负矩阵分解中,提出核非负矩阵分解方法(Kernel Non-negtive Matrix Factorization,KNMF)。核方法在多个领域得到了广泛应用,譬如:回归估计、概率密度估计、子空间分析等[8]。目前,只要满足Mercer条件,可以从一些简单的核函数设计出一个复杂核函数用于构造高维空间的核函数。KNMF将原始信息(图像)映射到特征空间后,再对新的数据表示进行非负矩阵分解,可选择的核函数包括极核函数、高斯核函数以及多项式核函数等。
相对于传统的非负矩阵分解,KNMF将原始信息(图像)映射到特征空间后再对新的数据表示进行非负矩阵分解,其表达式为:
式中,Φ( )是从原始空间(图像)到高维特征空间的映射,Φ(B)是B在特征空间中的映射值。而AΦ是特征空间中的基矩阵。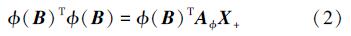
令R=ΦBtΦ(B)=K(B,B) 则有
1.3 多核非负矩阵分解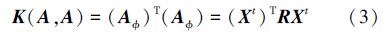

当故障样本特征含有众多异构信息、不规则的多维数据或数据特征空间分布差异较大时,利用单个简单核进行映射的方式对所有样本进行处理会产生很大的失真[9]。针对这些问题,近年来,涌现了一股研究核组合方法的热潮,即多核学习方法。多核模型具有更强的适应性,近几年的研究成果已经证明利用多核代替单核能够提高决策函数的可靠性,并其性能比单核模型更优[10]。多核的出现是为了能够处理多源特征数据或数据的异构特征的分类问题,通过将不同特性的核函数进行组合,使核函数之间可以优势互补,从而优化核函数的映射性能。
目前,多核构造方法大多是加权的多核合成方法,这类多核方法大多都是通过多个核函数的线性组合而成,如直接求和法、加权求和法、加权多项式扩展,对应表达式如下:
假定 k(x,z)是已知核函数, (x,z) 是它的归一化形式。
(x,z) 是它的归一化形式。
直接求和核:
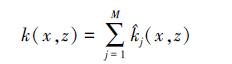
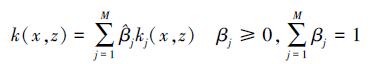
加权多项式求和核: k(x,z)=α1p(x,z)+(1-α)2q(x,z),p(x,z)是k(x,z) 的多项式扩展。
上述多核方法虽然可以实现异构数据源的融合,但是该类方法都是针对核函数的平稳组合,对所有输入样本,不同的核函数对应的权值以及数据集的局部分布是不变的。相当于对样本进行无差别化处理,选择性的忽略了不同数据集的差异性,可能会丢失原始矩阵信息,因此需要对传统的多核方法进行改进。
首先,重构特征核矩阵。新的核矩阵由原核矩阵和其他不同的核矩阵共同构成,生成的新核矩阵中包含原核矩阵的信息。 因此,原始核函数的性质得以保留。该合成核矩阵如表达(5)式所示:
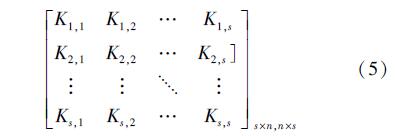
从表达式中可以看出,新矩阵对角线的数据即为原始核矩阵,其他所有元素是定义为 (Kt,t′)i,i=Kt,t′(xi,xi) 的2个不同核矩阵的混合,可由如下公式求得(以高斯核为例):
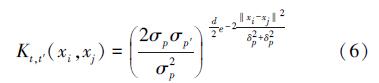
当 t=t′时,Kp,p≡Kp。
其次,应用多核的非平稳组合方法,通过线性权重分配方法,为每个输入样本分配不同的权重。本文采用多个基本核函数的凸组合,如表达(7)式所示:

而对于非平稳的合成核,其判别函数改进为表达式(8)。
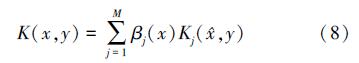
通过在最大熵判别框架下,使用一种大间隔因变量生成模型,使得因参数估计问题可以通过变化边界和一个内点优化过程来表示,并且相应的参数估计可以通过快速的序列最小优化算法来实现,从而使非平稳的多核学习方法具有更好的通用性。
2 多核支持向量机理论机械故障诊断过程中是关键环节之一就是分类器的设计,本文我们采用分类器支持向量机(support vector machine,SVM),SVM方法是由Vapnik及其合作者Boser、Guyon、Cortes及Scholkopf共同创造与发展起来的一种新的学习方法[11]。近年来关于SVM的研究,包括算法本身的改进和算法的实际应用正处于不断研究和完善阶段,目前已经成为机器学习领域的标准工具之一。支持向量机的网络结构分为三层,是一个多输入、单输出的学习机器,图 1为其体系结构。
 |
| 图 1 支持向量机体系结构图 |
如上图所示,首先确定训练样本作为支持向量机的输入,然后选择适当的核函数,将样本映射到高维的特征空间,根据优化问题求解出支持向量,最终得到相应的决策函数。SVM通过有限的数据信息在模型的复杂性和学习能力之间寻求最佳平衡,从而获得最优的推广能力,同时限制单元个体的学习能力,避免了过学习现象。其中,位于体系结构最底层的x1,x2,x3,…,xn是输入样本,y={-1,+1}。f(x) 是决策函数的输出。SVM通过某种非线性映射将低维的输入向量经过核函数映射到一个高维特征空间,并在高维空间中构造最优分类超平面,最优超平面将尽可能的对训练数据进行隔离,保证离超平面最近的向量与超平面之间的距离是最大的,即分类间隔最大化。
SVM通过解决如下的优化问题来寻找最优超平面:
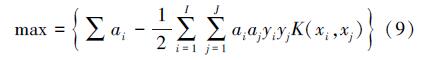
要求满足约束条件:
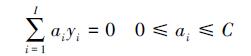
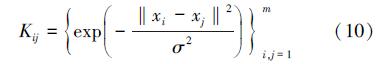
对于一个分类问题,所选择的用于描述样本的各个特征的识别能力并不相同,甚至毫无识别能力。因此,在解决分类问题时,应尽量突出那些识别能力较强的特征,抑制那些识别能力弱或无效的特征。传统SVM 在计算核函数时,对样本的各个特征平等对待,认为样本的各个特征在计算核函数时具有相等的权重,对解决分类问题的重要性相等。但是,当核函数被无效特征影响后,由其确定的特征空间势必会产生偏差,得到的最优超平面也无法具有良好的分类和推广能力。因此,如果核函数被无效特征影响,肯定会降低SVM的性能。
为了解决上面的问题,我们提出多核支持向量机(Multi-Kernel Support Vector Machine,MKSVM),其可对样本的各个特征赋予不同的核参数,如将高斯核基函数转变为多核高斯核基函数,如表达式(11)所示。当出现无效特征污染现象时,可通过对无效特征赋以较大的σi来削弱其对于特征空间的影响。
3 多核参数优化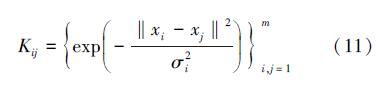
多核概念的引入为NMF和SVM方法增加了更多地需要优化的参数,因而参数的优化成为本文理论成功的关键,因此,我们提出基于遗传算法的参数优化方法。遗传算法并不直接处理MKNMF和MKSVM的参数,而是通过编码的方法将它们转换成遗传空间中的由基因按一定结构组成的染色体或个体。适应度函数是遗传算法进行自然选择的唯一依据,是遗传算法与优化目标联系的关键纽带。选择、杂交、变异均属于遗传操作因子,遗传算法反复执行以上等步骤直至满足某个收敛准则而停止迭代。如(12)式所示:

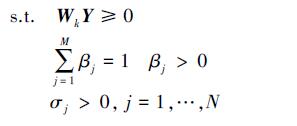
由式可知多核参数的优化过程涉及非负矩阵的分解和支持向量机分类,因此,多核参数寻优遵循的目标是:既要使多核非负矩阵分解合成系数最优,又要满足支持向量机的推广能力最强的原则。
本文通过采用二进制方式对参数进行编码,遗传算法选用离散化空间的方法进行,对多核非负矩阵分解进行寻优,并用分解得到的系数矩阵作为支持向量机的输入进行分类器设计,所涉及的优化参数列表如表 1所示:
| 名称 | 符号 | 范围 |
| 多核非负矩阵分解 高斯核参数 | lnσ | lnσ∈{-15,-14,…,0,…,14,15} |
| 多核非负矩阵分解 多项式核参数 | q | q∈Z+ |
| 多核非负矩阵分解 关键维数 | k | k∈Z+ |
| 多核非负矩阵分解 权系数 | ρ | ρ∈[0,1] |
| 支持向量机惩罚系数 | lnC | lnC∈{-15,-14,…,0,…,14,15} |
在应用遗传算法对参数优化的过程中,高斯核参数 σ和惩罚系数C均采用网格搜索,合成多项式核参数q和关键维数k都是整数。因此,该四个参数都只在整数网格上进行寻优,所以必须进行合理的编码,保证这四个参数的优化结果均为整数。为便于遗传算法寻优,将以上五个参数按照下图所示的方式进行二进制编码。图 2为编码方式示意图。
 |
| 图 2 编码方式 |
其中每个参数二进制位数由其对应的搜索范围来确定,lnσ和lnc的第一个二进制位为符号位。计算过程中采用一个编码和解码程序将实值的参数与遗传算法需要的二进制编码进行相互转换。权系数ρ对应的处于[0, 1]区间内的小数,因此解码时,需将二进制码所得的整数除以二进制编码所能表示的最大整数。遗传算法中相关参数设置如表 2所示:
根据以上知识,我们利用遗传算法对MKNMF-MKSVM 进行参数寻优。
具体应用过程中的算法流程为:①根据参数的搜索范围,确定各二进制编码的位数。②设定遗传算法的优化设置,产生初始种群。③对种群中各染色体进行解码,采用5重交叉检验方法,将训练数据随机划分为5个部分,其中4个部分作为训练样本用来训练模型,剩余的一个部分作为检验样本用来测试,计算5种交叉验证方法的平均识别率。由于遗传算法设定为寻找目标函数的最小值,适应度函数定义为1减去平均的识别率。计算过程中,采用的是整体识别率。④判断是否达到进化代数,如果达到则停止优化,输出最优参数,否则执行选择,交叉和变异等操作,产生下一代种群,并开始新一轮的优化过程。
4 基于多核非负矩阵分解的机械故障诊断模型根据上面的分析,本文采用多核非负矩阵分解提取机械故障图像的数字特征,以达到对高维图像的降维,并结合多核支持向量机对降维后的特征信息进行分类识别,从而实现对机械设备故障的智能诊断。具体流程如图 3所示。
 |
| 图 3 基于多核非负矩阵分解的机械故障诊断流程图 |
从上述MKNMF与MKSVM的机械故障诊断流程图可以看出,整个过程可分为如下几个步骤:
1)将反映设备不同运行状况的图像中随机选择一部分(或全部)组成样本集V,并对V应用MKNMF进行处理,得到标准图像集W;
2)将所有图像向标准样本集投影,得到每一幅图像对应的系数向量,这些系数向量共同形成降维后的样本集H;
3)应用H训练MKSVM,并对MKSVM中的核参数进行优化;
4)对于未知的状态,将其对应的图像向标准样本集W投影,得到系数向量H,然后将H送入训练好的多核SVM中,获得对状态的判定。在此过程中,分解算法会自动最大化地保留图像所包含的各种信息,这样就完全避免了故障诊断过程中的特征提取和选择难题,从而精确的对机械故障信息进行判断。
5 实验验证本文采用柴油机的非平稳信号的时频分析图像作为对象,验证本文提出的基于MKNMF-MKSVM的机械故障智能识别技术的有效性。实验是在上海柴油机厂生产的6135G 柴油机上进行的。图 4为数据采集系统示意图。
 |
| 图 4 数字采集系统示意图 |
本文分析的振动数据的采样频率均为24 kHz,所有采集到的数据均以文件的形式存放在计算机硬盘上。实际运行中的柴油机故障数据比较难以收集,出于实验研究的目标需要,人为地设置了7种柴油机气阀故障。
实验在6135柴油机第2缸上进行,模拟了7种气阀常见故障,加上正常状态,总共测试并获取了气阀机构8种状态下的缸盖振动信号。测量时,柴油机状态为空载,转速为1 500 rad/min。8 种气阀状态对应的气门间隙等参数如表 3所示。
| /mm | ||||||
| 编号 | 进气门 间隙 | 排气门 间隙 | 编号 | 进气门 间隙 | 排气门 间隙 | |
| 1 | 0.30 | 0.30 | 5 | 0.30 | 新气门 | |
| 2 | 0.30 | 0.06 | 6 | 0.06 | 0.06 | |
| 3 | 0.30 | 0.50 | 7 | 0.06 | 0.50 | |
| 4 | 0.30 | 开口 | 8 | 0.50 | 0.50 | |
| 注:4×1(0.30)(0.30) | ||||||
对柴油机故障的每一种状态进行重复采样获得38个信号,然后采用S变换、Wigner-Ville分布、锥形核分布等13种时频分析方法分别处理(如表 4所示),相应得到330×630个像素点的时频图像(时频矩阵)。
| 时频分析方法 | 英文缩写 |
| S变换 | ST |
| 基于径向高斯核的分布 | RGKBD |
| 改进的基于径向高斯核的分布 | IRGKBD |
| 谱图时频图像 | SPECTROGRA |
| 伪Wigner-Ville分布 | PWVD |
| Wigner-Ville分布 | WVD |
| 基于自适应最优核的分布 | AOKBD |
| Choi-Williams分布 | CWD |
| 平滑伪Wigner-Ville分布 | SPWVD |
| 基于径向余弦核的分布 | RCKBD |
| 锥形核分布 | CKD |
| 重排平滑伪Wigner-Ville分布 | RSPWVD |
| 模糊函数 | AF |
计算流程如下:
1)通过矩阵重排操作,将每一幅时频矩阵由330×630维变形为297 900×1维列向量,并对其进行归一化处理。
2)总体样本数为146,从中随机抽取1/3,组成训练样本集 V。
3)对V进行多核非负矩阵分解,获得特征矩阵W。考虑到核函数的全局特性与局部特性的均衡,采用一个高斯核与一个多项式核的线性组合,即:
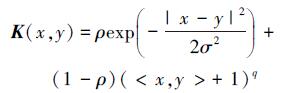
式中,σ为高斯核参数,ρ为核加权系数,q为多项式核参数,k是降低的维数。参数值的选择采用遗传算法进行优化,可以得到对应的最优核参数。
4)将得到的系数矩阵H与对应故障类别作为MKSVM分类器的训练样本,采用5重交叉验证的方法进行训练,其中MKSVM采用线性高斯核,最优的惩罚参数C也是由遗传算法在网格点上搜索得到。
5)将所有剩余2/3幅时频图像向基矩阵W投影,得到对应的系数向量矩阵H。将得到的系数矩阵代入训练好的MKSVM分类器进行分类试验,得到最优分解参数对应的识别率。
虽然本文涉及多个不同的故障模式,但故障诊断方法优越性不能看其只对某一个故障模式的识别情况,而是对所有故障模式都具有较好的识别率。因此,对单一故障的识别率并没有太大的参考意义,给出的结果均为所有故障模式的平均识别率。如表 5所示。
| 序号 | 时频表示类型 | 相关最优参数 | 最优平均识别率 | ||||
| lnσ | q | k | ρ | lnC | Acc | ||
| 1 | RSPWVD | 1 | 4 | 63 | 0.703 1 | -6 | 0.918 7 |
| 2 | CKBD | -10 | 12 | 51 | 0.937 5 | -6 | 0.926 8 |
| 2 | RGKBD | 9 | 7 | 56 | 0.312 5 | -4 | 0.916 1 |
| 4 | IRGKBD | 10 | 13 | 59 | 0.828 1 | -7 | 0.923 0 |
| 5 | AM | -13 | 13 | 58 | 0.406 3 | -8 | 0.989 7 |
| 6 | AOK | -14 | 6 | 55 | 0.421 9 | -5 | 0.929 5 |
| 7 | CKD | 7 | 2 | 53 | 0.960 9 | -8 | 0.926 8 |
| 8 | CWD | 12 | 13 | 60 | 0.226 6 | -7 | 0.923 1 |
| 9 | PWVD | -8 | 12 | 54 | 0.921 9 | -5 | 0.940 3 |
| 10 | SPECTROGRAM | 3 | 15 | 39 | 0.828 1 | -6 | 0.902 5 |
| 11 | SPWVD | -7 | 3 | 51 | 0.812 5 | -9 | 0.912 6 |
| 12 | ST | -5 | 13 | 55 | 0.648 4 | -10 | 0.959 6 |
| 13 | WVD | -2 | 3 | 44 | 0.437 5 | -8 | 0.953 2 |
从上表可以看出,针对不同的时频表示类型,基于多核非负矩阵分解的机械故障诊断方法的识别率均达90%以上,具有较高的识别率。对高维图像的降维效果显著,体现出良好的降维和识别能力。另一方面,由于高斯核参数及惩罚参数都采用网格搜索,改进两参数的搜索范围有可能进一步提高识别率。
同时,我们对时频图像分别采用ONMF、KNMF和MKNMF方法,基于图像信息的机械设备故障智能诊断模型所示的方法进行处理。实验过程如下:
1)对任意一种时频分析方法,通过矩阵重排操作,将每一幅时频矩阵由330×630维变形为270 900×1维列向量,并对其进行归一化处理。
2)总体样本数为146,从中随机抽取1/3,组成训练样本集V。
3)对分别进行ONMF、KNMF和MKNMF,获得特征矩阵W,其维数为:207 900×r,其中r表示特征维数,其取值影响分解的结果及后续的识别精度,本实例中选用的关键特征维数r=40。
4)将得到的系数矩阵H与对应故障类别作为MKSVM分类器的训练样本,采用五重交叉验证的方法进行训练,其中SVM采用线性核,惩罚参数C=1。
5)将所有剩余2/3幅时频图像向基矩阵W投影,得到对应的系数向量矩阵H,其维数为,则每一幅时频图像可以用相应的系数向量H表示。
6)将得到的系数矩阵代入训练好的MKSVM分类器进行分类试验,以识别正确率和运行时间作为指标评价本文方法的性能。重复进行100次试验以削弱随机因素的影响。
图 5是AM时频表示的试验结果,其中KNMF的核函数为高斯核,σ=0.35;为简化计算Multi-KNMF的核函数均选择高斯核,核函数采用直接相加的合成方式。对应的核参数为0.15,0.35,0.75。 由图可知,在这100次实验中,MKNMF对机械故障信息的分类正确率基本上保持在85%以上,平均分类正确率为0.9;KNMF分类正确率基本保持在75%以上,平均分类正确率为0.85;ONMF分类正确率基本保持在70%以上,平均分类正确率为0.7。同时我们对其分类时间进行统计,分别为7 min、9 min、4 h。因此,实验证明,MKNMF对于机械故障图像的识别率和识别时间要优于KNMF和ONMF,具有较强故障诊断能力和效率。
 |
| 图 5 ONMF、KNMF和MKNMF对比分析实验 |
针对传统机械诊断方法以无法高效处理高维监测数据,本文提出了基于多核非负矩阵分解的机械故障诊断方法,通过多核非负矩阵对高维信息进行降维,解决了传统单核非负矩阵分解方法对不规则高维数据处理会产生失真的问题;然后运用多核支持向量机对特征信息进行分类分析并判断故障分类。实验证明,基于多核非负矩阵分解机械故障诊断方法可降低原始数据特征的维数,提高运算效率以及故障诊断的识别率,具有广泛的应用前景和推广价值。
| [1] | Giger M L, Karssemeijer N, Schnabel J A. Breast Image Analysis for Risk Assessment[J]. Detection, Diagnosis, and Treatment of Cancer Annual Review of Biomedical Engineering, 2013, 15:327-357 |
| [2] | Peng Z K, Meng G, Chu F L. Improved Wavelet Reassigned Scalograms and Application for Modal Parameter Estimation[J]. Shock and Vibration, 2011, 18:299-316 |
| Click to display the text | |
| [3] | Wang D. Support Vector Data Description for Fusion of Multiple Health Indicators for Enhancing Gearbox Fault Diagnosis and Prognosis[J]. Measurement Science and Technology, 2011, 22(2):025-102 |
| Click to display the text | |
| [4] | 朱丽,龙兵,刘震.基于ARMA的雷达发射机故障预测及其实现[J].计算机测量与控制, 2010, 18(11):2460-2461 Zhu Li, Long Bin, Liu Zhen. ARMA-Based Fault Prediction for Radar Transmitter and Its Realization Method[J].Computer Measurement & Control, 2010, 18(11):2460-2461(in Chinese) |
| Cited By in Cnki (2) | Click to display the text | |
| [5] | Liu Y H, Liu Y C, Chen Y Z. High-Speed Inline Defect Detection for TFT-LCD Array Process Using a Novel Support Vector Data Description. Expert Systems with Applications, 2011, 38(5):6222-6231 |
| Click to display the text | |
| [6] | 罗颂荣,程军圣,杨宇.基于本征时间尺度分解和变量预测模型模式识别的机械故障诊断[J].计算机测量与控制, 2013, 32(13):43-48 Luo Songrong, Cheng Junsheng, Yang Yu. Machine Fault Diagnosis Method Using ITD and Variable Predictive Model-Based Class Discrimination[J]. Journal of Vibration and Shock, 2013, 32(13):43-48(in Chinese) |
| Cited By in Cnki (9) | Click to display the text | |
| [7] | 卢进军.基于非负矩阵分解的相关反馈图像检索算法[J].上海交通大学学报,2005,39(4):578-581 Lu Jinjun. Non-Negative Matrix Factorization Based Relevance Feedback Algorithm in Image Retrieval[J]. Journal of Shanghai Jiaotong University, 2005, 39(4):578-581(in Chinese) |
| Cited By in Cnki (27) | Click to display the text | |
| [8] | 汪洪桥,蔡艳宁.多尺度核方法的自适应序列学习及应用[J].模式识别与人工智能, 2011(01):72-81 Wang Hongqiao, Cai Yanning. Adaptive Sequence Learning and Applications for Multi-Scale Kernel Method[J]. Pattern Recognition and Artificial Intelligence, 2011(01):72-81(in Chinese) |
| Cited By in Cnki (9) | Click to display the text | |
| [9] | 亓晓振,王庆.一种基于稀疏编码的多核学习图像分类方法[J].电子学报,2012, 40(4):773-779 Qi Xiaozhen, Wang Qing. An Image Classification Approach Based on Sparse Coding and Multiple Kernel Learning[J]. Acta Electronica Sinica, 2012, 40(4):773-779(in Chinese) |
| Cited By in Cnki (23) | Click to display the text | |
| [10] | 李谦,景丽萍,于剑.基于多核学习的投影非负矩阵分解算法[J].计算机科学,2014, 41(2):64-67 Li Qian, Jing Liping, Yu Jian. Multi-Kernel Projective Nonnegative Matrix Factorization Algorithm[J]. Computer Science, 2009,32(8):2014, 41(2):64-67(in Chinese) |
| Cited By in Cnki (1) | Click to display the text | |
| [11] | 张周锁,李凌均,何正嘉.基于支持向量机的机械故障诊断方法研究[J].西安交通大学学报, 2002, 36(2):1303-1306 Zhang Zhousuo, Li Lingjun, He Zhengjia. Research on Diagnosis Method of Machinery Fault Based on Support Vector Machine[J]. Journal of Xi'an Jiaotong University, 2002, 36(2):1303-1306(in Chinese) |
| Cited By in Cnki (168) | Click to display the text |